Lab Guide: Implementing GPU Pricing Tiers with Kueue
This lab demonstrates how to use Kueue to implement a multi-tiered service model for GPU workloads, simulating "reserved" and "on-demand" pricing plans.
1. Prerequisites
-
OpenShift AI Operator: Ensure the OpenShift AI Operator is installed.
-
GPU Worker Node: You need at least one worker node with a time-sliced NVIDIA A10G GPU, as configured in the previous lab. On AWS, a
g5.2xlargeinstance is suitable. -
GPU Node Taint: The GPU node must be tainted.
This was done during the bootstrap process. If you need to reapply the taint, use this command:
oc adm taint nodes <your-gpu-node-name> nvidia.com/gpu=Exists:NoSchedule --overwrite
2. Use Case Description
A common business requirement is to offer different service levels for expensive resources like GPUs. This lab simulates two such tiers:
-
Reserved Plan: For premium customers who pay for guaranteed, immediate access to their allocated GPU resources. These workloads are critical and cannot wait in a queue.
-
On-Demand Plan: For general users who pay per use. These workloads are less critical and can wait for GPU capacity to become available.
Kueue will enforce these service levels, ensuring reserved workloads are prioritized and on-demand jobs are admitted based on available capacity.
|
While this lab focuses on GPUs, Kueue can manage quotas for any resource type, including CPU, memory, and custom resources. |
Customers may need reserved capacity when their workloads are critical, have strict deadlines, or require predictable performance. Industries such as financial services for high-frequency trading, scientific research with long-running simulations, or media companies for rendering and encoding often need guaranteed access to resources to avoid delays and maintain business continuity. Reserved capacity ensures these users always have the compute power they’ve paid for, eliminating the risk of waiting for resources to become available.
On-demand capacity is suitable for customers with intermittent, non-critical, or variable workloads. This model is ideal for tasks like ad-hoc data analysis, development and testing environments, or temporary spikes in demand from a product launch.
Users pay only for what they use, which can be more cost-effective than reserving resources that may sit idle. The trade-off is that they might have to wait for resources during peak usage times, but for these types of workloads, the flexibility and lower cost outweigh the potential for delays.
2.1. Plan’s Summary 📋
Reserved Plan: A customer who pays for a reserved plan has a guarantee of resources. In this model, you would create a guaranteed ResourceFlavor that a user’s workloads would request. Kueue would prioritize these workloads, ensuring they get scheduled as long as the reserved capacity is available. 🔒
On-Demand Plan: This model is for users who pay per use and may need to wait for available resources. You would create an `on-demand ResourceFlavor for these users. Kueue would schedule these jobs only after all higher-priority (reserved) jobs have been scheduled. ⏳
|
Not just for GPU resources
The focus in this Lab is on the GPU resources but a Kueue does support other resource types as well. |
3. Solution Overview
We will use Kueue’s ResourceFlavor and ClusterQueue objects to create our two-tiered system.
-
ResourceFlavor: We will define a
ResourceFlavorthat targets our specific time-sliced A10G GPUs using anodeLabelselector. This ensures that all GPU requests are scheduled on the correct hardware. -
ClusterQueues for Tiers:
-
Reserved Tier: Each reserved customer (
customer-a,customer-b) will get their own dedicatedClusterQueue. ThenominalQuotain each queue defines their guaranteed number of GPU slices. This provides strong isolation and guarantees. -
On-Demand Tier: A single
ClusterQueuewill serve all on-demand users. This queue will have anominalQuotarepresenting the total pool of GPUs available for on-demand use.
-
|
On Cohorts and Resource Sharing
Kueue’s |
As stated in the official Kueue docs [1]:
Resources in a cluster are typically not homogeneous. Resources could differ in:
Pricing and availability (for example, spot versus on-demand VMs)
Architecture (for example, x86 versus ARM CPUs)
Brands and models (for example, Radeon 7000 versus Nvidia A100 versus T4 GPUs)
A ResourceFlavor is an object that represents these resource variations and allows you to associate them with cluster nodes through labels, taints and tolerations.
Kueue Documentation, Version 0.13.4
3.1. Kueue Configuration
In this scenario, the label selector is nvidia.com/gpu.product: NVIDIA-A10G-SHARED:
cat <<EOF | oc apply -f -
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: nvidia-a10g-shared
spec:
nodeLabels:
nvidia.com/gpu.product: NVIDIA-A10G-SHARED
EOF|
Configuration of Cohorts
Usually the customer would like to increase the usage of the GPUs as much as possible. Therefore it would be a good solution to borrow GPU quota between cluster queues. As stated in the official Kueue docs [1]: Cohorts give you the ability to organize your Quotas. ClusterQueues within the same Cohort (or same CohortTree for Hierarchical Cohorts) can share resources with each other.
— Kueue
Kueue Documentation, Version 0.13.4 |
This ClusterQueue guarantees 4 virtual GPU for customer A.
cat <<EOF | oc apply -f -
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: reserved-capacity-customer-a
spec:
# cohort: gpu-sharing-cohort
namespaceSelector: {}
resourceGroups:
- coveredResources:
- "nvidia.com/gpu"
flavors:
- name: nvidia-a10g-shared
resources:
- name: "nvidia.com/gpu"
nominalQuota: 4
# borrowingLimit: 12 # Allows borrowing up to 5 additional GPUs - not supported yet
EOFThis ClusterQueue guarantees 4 virtual GPU for customer B.
cat <<EOF | oc apply -f -
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: reserved-capacity-customer-b
spec:
# cohort: gpu-sharing-cohort
namespaceSelector: {}
resourceGroups:
- coveredResources:
- "nvidia.com/gpu"
flavors:
- name: nvidia-a10g-shared
resources:
- name: "nvidia.com/gpu"
nominalQuota: 4
# borrowingLimit: 12 # Allows borrowing up to 5 additional GPUs - not supported yet
EOFThis ClusterQueue gurantees 8 GPUs for all customers using the on-demand tier.
cat <<EOF | oc apply -f -
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: on-demand-capacity
spec:
# cohort: gpu-sharing-cohort
namespaceSelector: {}
resourceGroups:
- coveredResources:
- "nvidia.com/gpu"
flavors:
- name: nvidia-a10g-shared
resources:
- name: "nvidia.com/gpu"
nominalQuota: 8
# borrowingLimit: 8 # Allows borrowing up to 5 additional GPUs - not supported yet
EOFWith this configuration, each customer has one or more guaranteed virtual GPUs.
4. Verify the Solution
The next step is to verify the configuration.
4.1. Create verification "infrastructure"
First create a namespace and a LocalQueue pointing to the correct ClusterQueue for each customer.
cat <<EOF | oc apply -f -
kind: Namespace
apiVersion: v1
metadata:
name: reserved-team-a
labels:
kubernetes.io/metadata.name: reserved-team-a
kueue.openshift.io/managed: 'true'
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: reserved-team-a
name: reserved-team-a
spec:
clusterQueue: reserved-capacity-customer-a
EOFcat <<EOF | oc apply -f -
kind: Namespace
apiVersion: v1
metadata:
name: reserved-team-b
labels:
kubernetes.io/metadata.name: reserved-team-b
kueue.openshift.io/managed: 'true'
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: reserved-team-b
name: reserved-team-b
spec:
clusterQueue: reserved-capacity-customer-b
EOFcat <<EOF | oc apply -f -
kind: Namespace
apiVersion: v1
metadata:
name: on-demand-team-a
labels:
kubernetes.io/metadata.name: on-demand-team-a
kueue.openshift.io/managed: 'true'
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: on-demand-team-a
name: on-demand-team-a
spec:
clusterQueue: on-demand-capacity
EOFoc create -f <file-name>.yaml)apiVersion: batch/v1
kind: Job
metadata:
generateName: reserved-capacity-customer-a
namespace: <namespace>
labels:
kueue.x-k8s.io/queue-name: <local-queue-name>
spec:
template:
spec:
containers:
- name: sleeper
image: registry.access.redhat.com/ubi9/ubi:latest
command: ["/bin/sleep"]
args: ["300"] # 5 minutes
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
backoffLimit: 4Tasks 📋:
-
🔎 Verify that each customer can’t exceed the number of assinged GPUs
-
❌ Remove the label
kueue.x-k8s.io/queue-name: <local-queue-name>from theJoband test to "trick the system". Try to submit Jobs to consume more GPUs then allowed. -
⌛️ Add Memory allocation to the
ClusterQueueof Customer A, to limit the allowed memory to 1Gi - verify the configuration. -
➕ Add another customer consuming
on-demandresources - verify each of the teams consumingon-demandcan get all of the GPUs (8 GPUs is the maximum configured in theClusterQueue) while the other team is on vacation.
|
Use the dashboard which was created earlier to get insights into the state of different resources. Enable port forwarding to access http://localhost:3000/. |
Hint: Use the dashboard which was created earlier.
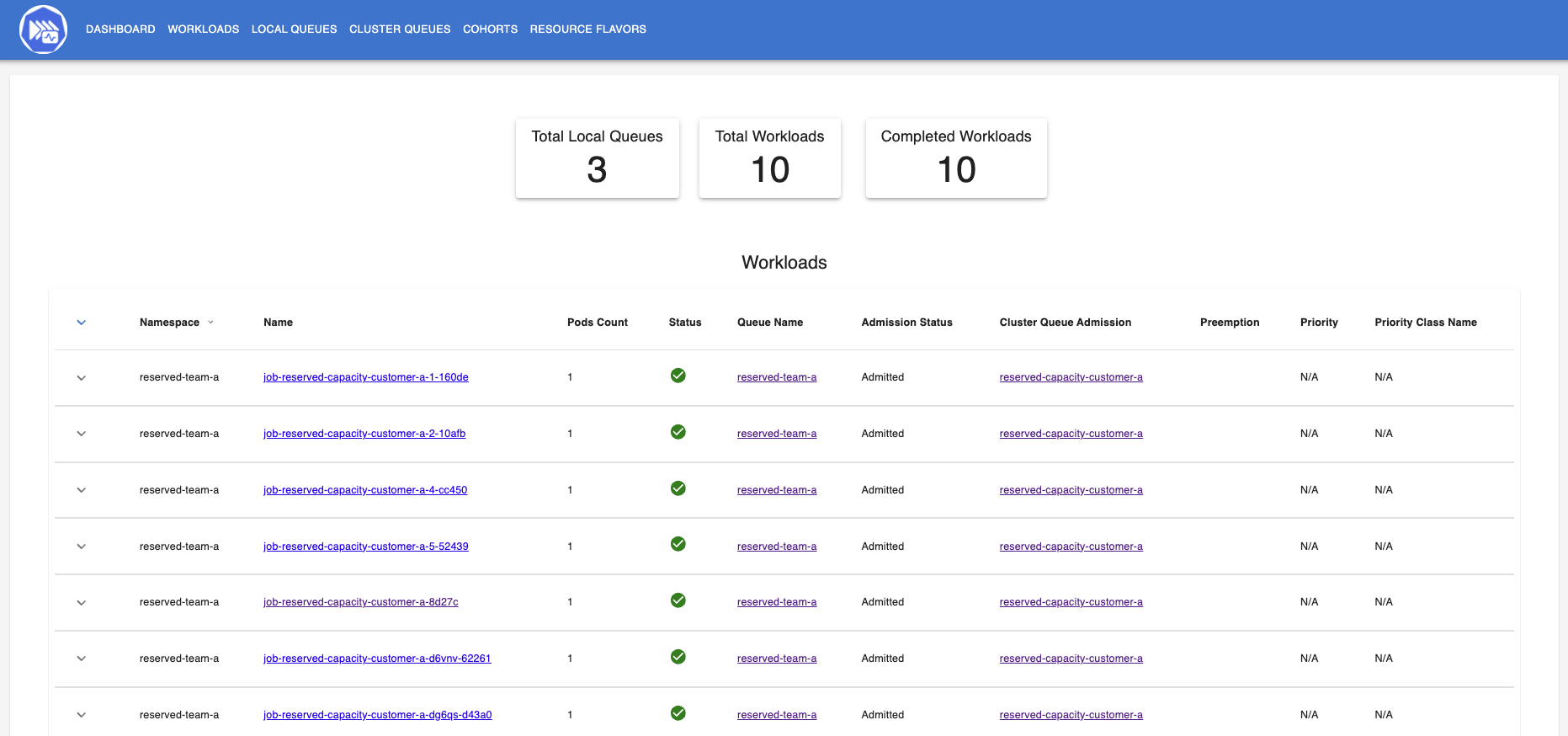
kubectl -n kueue-system port-forward svc/kueue-kueueviz-backend 8080:8080 &
kubectl -n kueue-system set env deployment kueue-kueueviz-frontend REACT_APP_WEBSOCKET_URL=ws://localhost:8080
kubectl -n kueue-system port-forward svc/kueue-kueueviz-frontend 3000:8080Open http://localhost:3000/ in the browser.
References
-
[1] Kueue. Documentation. Version May 15, 2025. Available from: https://kueue.sigs.k8s.io/docs/overview/.
-
[2] AI on OpenShift Contrib Repo. Kueue Preemption Example. Available from: https://github.com/opendatahub-io-contrib/ai-on-openshift.
5. Cheat Sheet
If you need the jobs to test the configuration, you can create them with the following commands:
Cheat Sheet - Create Jobs
cat <<EOF | oc create -f -
apiVersion: batch/v1
kind: Job
metadata:
generateName: reserved-capacity-team-a-
namespace: reserved-team-a
labels:
kueue.x-k8s.io/queue-name: reserved-team-a
spec:
template:
spec:
containers:
- name: sleeper
image: registry.access.redhat.com/ubi9/ubi:latest
command: ["/bin/sleep"]
args: ["300"] # 5 minutes
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
backoffLimit: 4
---
apiVersion: batch/v1
kind: Job
metadata:
generateName: reserved-capacity-team-b-
namespace: reserved-team-b
labels:
kueue.x-k8s.io/queue-name: reserved-team-b
spec:
template:
spec:
containers:
- name: sleeper
image: registry.access.redhat.com/ubi9/ubi:latest
command: ["/bin/sleep"]
args: ["300"] # 5 minutes
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
backoffLimit: 4
---
apiVersion: batch/v1
kind: Job
metadata:
generateName: on-demand-team-a-
namespace: on-demand-team-a
labels:
kueue.x-k8s.io/queue-name: on-demand-team-a
spec:
template:
spec:
containers:
- name: sleeper
image: registry.access.redhat.com/ubi9/ubi:latest
command: ["/bin/sleep"]
args: ["300"] # 5 minutes
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
backoffLimit: 4
EOF