Monitoring Data Science Models
To ensure that machine-learning models are transparent, fair, and reliable, data scientists can use TrustyAI in OpenShift AI to monitor their data science models.
TrustyAI is an open source Responsible AI toolkit supported by Red Hat and IBM. TrustyAI provides tools for a variety of responsible AI workflows, such as:
-
Local and global model explanations
-
Fairness metrics
-
Drift metrics
-
Text detoxification
-
Language model benchmarking
-
Language model guardrails
RHOAI currently provides TrustyAi capabilities for monitoring model bias, monitoring data drift, evaluating large language models and guardrails orchestrator.
Monitoring Model Bias
Monitoring model bias means detecting algorithmic deficiencies that might skew the outcomes or decisions that the model produces. Importantly, this type of monitoring helps you to ensure that the model is not biased against particular protected groups or features.
RHOAI currently supports the following bias metrics:
-
Statistical Parity Difference (SPD) is the difference in the probability of a favorable outcome prediction between unprivileged and privileged groups
-
Disparate Impact Ratio (DIR) is the ratio of the probability of a favorable outcome prediction for unprivileged groups to that of privileged groups.
Models can be monitored for whether they become biased over a specified fields (e.g. gender, age, etc.) with privileged and unprovileged groups specifying a set of values for those fields (e.g. age<30). Over time SPD ideally should be 0 to indicate the complete fairness, however values in the range -0.1 - 0.1 are considered reasonable.
In the following example you can see SPD metrics for two models showing model bias for gender attribute.
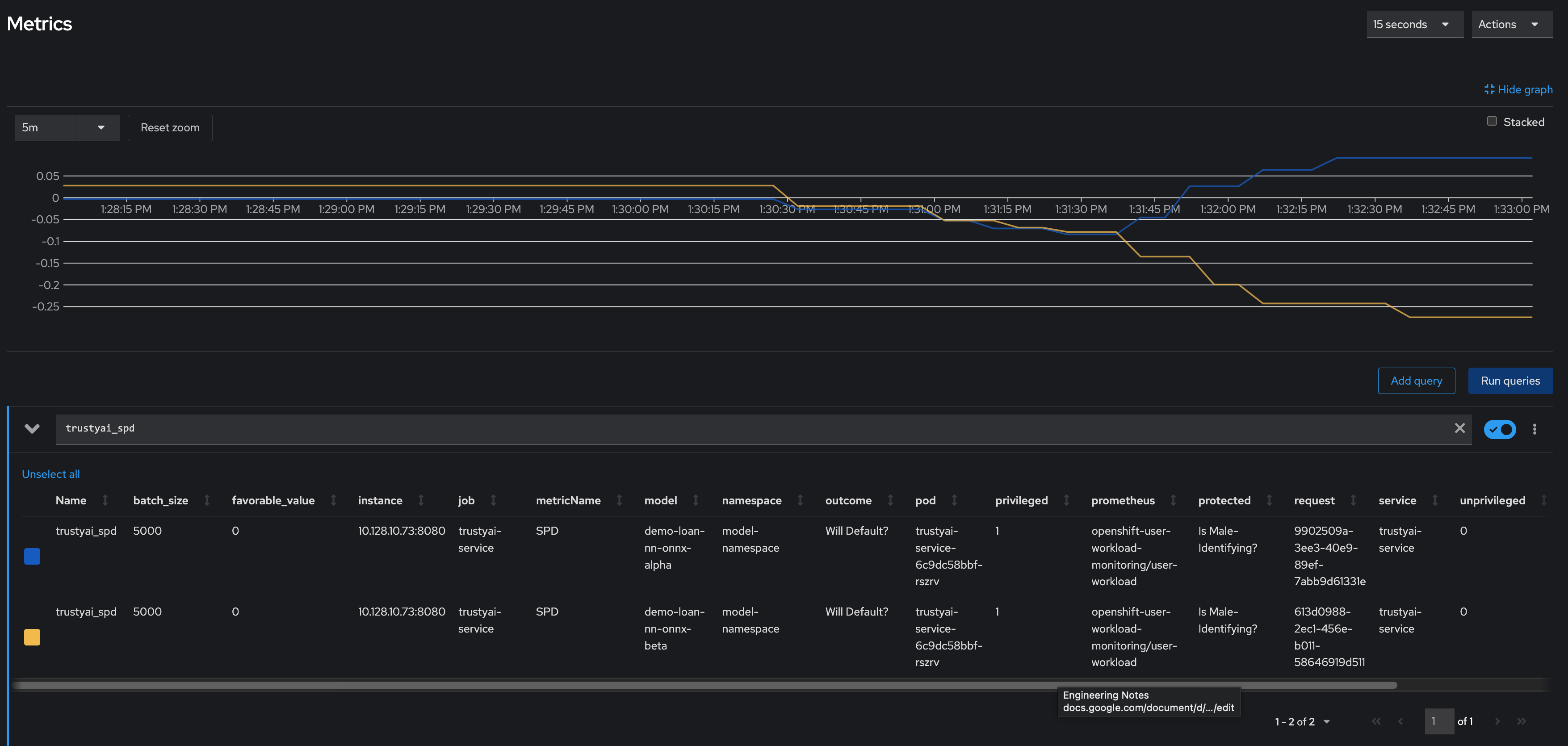
You can see that two models have a different fairness when deployed in the real word. First model (blue line) shows acceptable fairness within -0.1 - 0.1 range. Second model (yellow line) quickly went out of range showing metrics value of less than -0.25 - indicating that non-male-identifying applicants were 25% less likely to get a favorable outcome.
Monitoring Data Drift
Most machine learning models are highly sensitive to the distribution of the data they receive; that is, how the individual values of various features in inbound data compare to the range of values seen during training. Often, models will perform poorly on data that looks distributionally different than the data it was trained on. The analog here is studying for an exam; you’ll likely perform well if the exam material matches what you studied, and you likely won’t do particularly well if it doesn’t match. A difference between the training data (the material you studied) and the real-world data received during deployment (the exam material) is called data drift.
RHOAI currently supports the following data drift metrics:
-
MeanShift metric calculates the per-column probability that the data values in a test data set are from the same distribution as those in a training data set (assuming that the values are normally distributed). This metric measures the difference in the means of specific features between the two datasets.
-
FourierMMD metric provides the probability that the data values in a test data set have drifted from the training data set distribution, assuming that the computed Maximum Mean Discrepancy (MMD) values are normally distributed.
-
KSTest metric calculates two Kolmogorov-Smirnov tests for each column to determine whether the data sets are derived from the same distributions.
-
ApproxKSTest metric performs an approximate Kolmogorov-Smirnov test
Data drift can be monitored for specified model inputs and outputs showing model performance for inbound data in comparison to data that was used during training.
In the following example you can see MeanShift metrics for a set of input and output data for training and test datasets.
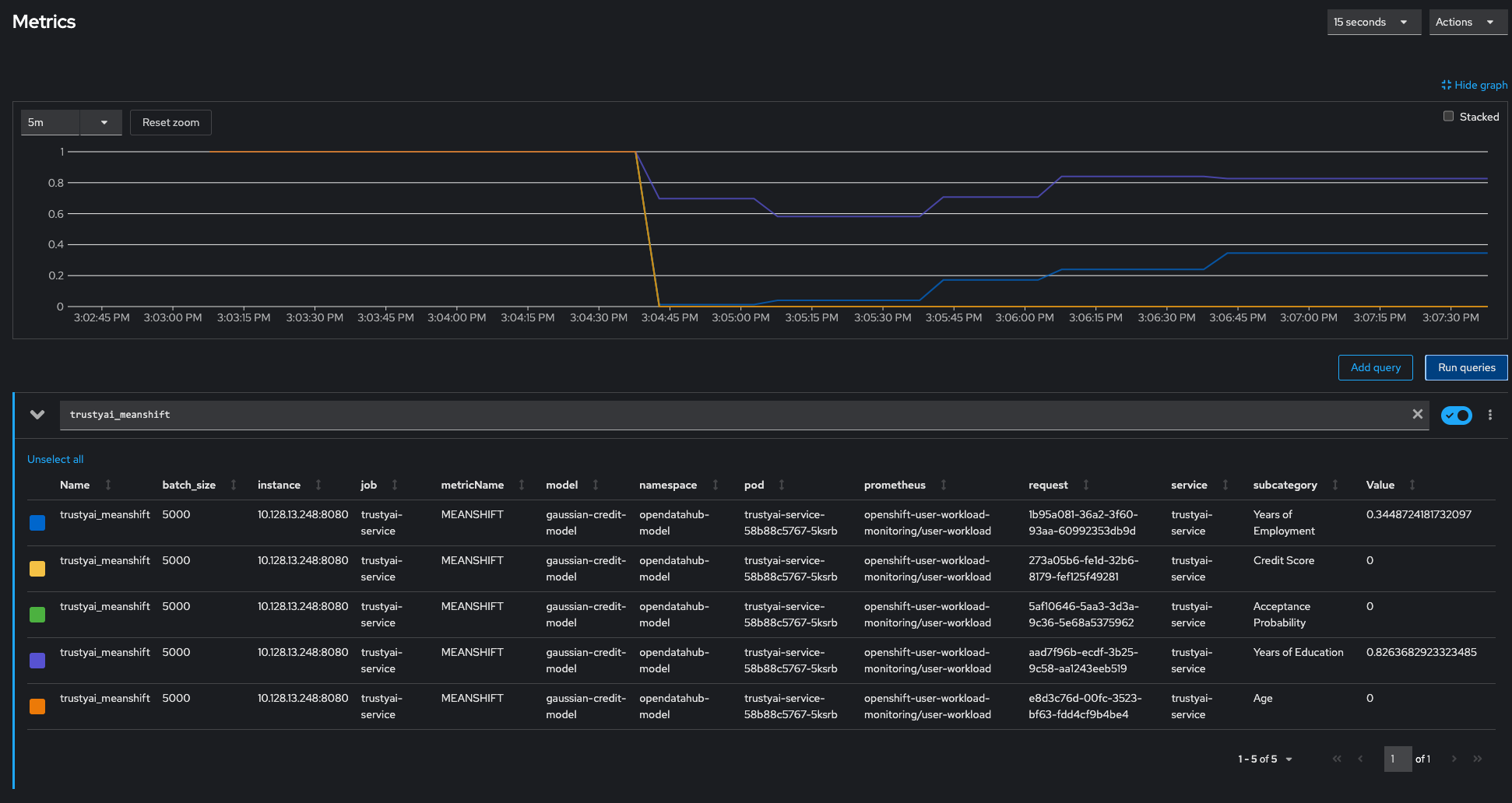
You can see that metrics values for Credit Score, Age, and Acceptance Probability have all dropped to 0 indicating that there is a statiscically very high likelyhood that the test data came from a different distribution than the training data. Years of Employment and Years of Education values are dropped to 0.34 and 0.82 indicating that ther is not too much drift for these values.
Evaluating Large Language Models
Red Hat OpenShift AI now offers Language Model Evaluation as a Service (LM-Eval-aaS), in a feature called LM-Eval. LM-Eval provides a unified framework to test generative language models on a vast range of different evaluation tasks.
Guardrails Orchestration
The TrustyAI Guardrails Orchestrator service is a tool to invoke detections on text generation inputs and outputs, as well as standalone detections.
Guardrails are policies, frameworks, and technologies designed to ensure AI systems, particularly Large Language Models (LLMs), operate ethically, legally, and safely, preventing harm, bias, or misuse.
RHOAI introduced TrustyAI Guardrails Orchestrator as technology preview in v.2.18.