RAG with LLM
What is Retrieval-Augmented Generation (RAG)
Large Language Models (LLMs) are trained using a large world of knowledge. This knowledge is static and compressed into the Language Model. It doesn’t get updated when new information becomes available or changes. The knowledge is also general and not really specialized to a specific topic. When you ask a question to the LLM, the answer it gives you may be incorrect or you may want to know how it came up with the answer. One way we can make the LLM smarter and more accurate is by using Retrieval-Augmented Generation with the LLM.
RAG augments the LLM by giving it a specialized and mutable knowledge base to use.
Retrieval-Augmented Generation vs Retraining
RAG is an architectural approach that retrieves relevant information from external sources and uses it as context for the LLM to generate responses. This method is particularly useful in dynamic data environments where information is constantly changing. RAG ensures that the LLM’s responses remain up-to-date and accurate by querying external sources in real-time.
Retraining LLMs involves fine-tuning a pre-trained model on a specific dataset or task to adapt it to a particular domain or application. This approach is useful when the LLM needs to develop a deep understanding of a specific domain or task.
Retrieval-Augmented Generation and retraining Large Language Models are two approaches to enhance the performance of LLMs in various applications. While both methods have their strengths and weaknesses, they cater to different needs and scenarios.
Retrieval-Augmented Generation
Advantages:
-
Agility: RAG allows for quick adaptation to changing data without the need for frequent model retraining.
-
Up-to-date responses: RAG ensures that the LLM’s responses are based on the latest information available.
-
Flexibility: RAG can be applied to various domains and tasks, making it a versatile approach.
Disadvantages:
-
Complexity: RAG requires the development of a robust retrieval system and the integration of external knowledge sources.
-
Dependence on external sources: RAG’s effectiveness relies on the quality and relevance of the external knowledge sources.
Retraining Large Language Models
Advantages:
-
Domain-specific knowledge: Retraining allows the LLM to develop a deep understanding of a specific domain or task.
-
Improved accuracy: Fine-tuning can lead to improved accuracy in specific tasks or domains.
-
Reduced hallucinations: Retraining can help reduce hallucinations and improve the LLM’s ability to generate accurate and relevant responses.
Disadvantages:
-
Static data snapshots: Fine-tuned models become static data snapshots during training and may quickly become outdated in dynamic data scenarios.
-
Limited recall: Fine-tuning does not guarantee recall of knowledge, making it unreliable in certain situations. Choosing between RAG and Retraining
When deciding between RAG and retraining, consider the following factors:
-
Dynamic data environment: If the data is constantly changing, RAG is a better choice.
-
Domain-specific knowledge: If the LLM needs to develop a deep understanding of a specific domain or task, retraining is a better option.
-
Agility and up-to-date responses: If agility and up-to-date responses are crucial, RAG is a better choice.
-
Complexity and development time: If development time and complexity are concerns, retraining might be a better option.
Both RAG and Fine-Tuning Combined

Combining RAG and fine-tuning can be a powerful approach. By fine-tuning an LLM on a specific task or domain and then using RAG to retrieve relevant information, you can achieve the best of both worlds.
Advantages:
-
Improved performance: Combining RAG and fine-tuning can lead to improved performance on specific tasks or domains.
-
Domain knowledge: Fine-tuning can help the LLM acquire domain-specific knowledge, while RAG can ensure that the responses are up-to-date and accurate.
Disadvantages:
-
Complexity: Combining RAG and fine-tuning can be complex and require significant resources.
-
Limited scalability: Combining RAG and fine-tuning may not be scalable for large-scale applications.
How RAG with LLM works
Retriever and Knowledge Base and Text Embeddings
The process of getting information from the knowledge base is as such:
-
The user inputs a question.
-
The user query gets passed to the RAG module.
-
The RAG module connects to knowledge base and grabs pieces of information that are relevant to user query and creates a prompt for the LLM.
-
The prompt then gets passed to the LLM.
-
LLM’s answer gets passed back to the user.
In RAG, the data is stored (usually) in a vector database. The process is as follows:
-
Load the documents or raw information. The documents are collected into a ready to parse format such as text. (LLMs understand text)
-
Chunk or split the documents. We can’t dump all the documents to the LLM. Smaller chunks allows the LLM to consume better and relevant information.
-
Take these chunks, and translate it to a vector or a set of numbers that represent the meaning of the text (text embeddings).
-
Load these vectors into the vector database.
What are Text Embeddings?
Text embeddings are vectors or arrays of numbers that represent the semantic meaning and context of words or text.
Similar concepts are grouped closed together.
-
Plants, trees, flowers
-
Baseball, basketball, pickleball
-
Hamburger, hotdog, chip
These words/concepts will be turned into a set of numbers and will be stored in the vector database. Plants, trees and flowers should be grouped closer together in the database. Each of these items is a piece of info in our knowledge base: description of a tree, description of flower, etc. When we do a text embedding-based search, the text embedding that represent closest to the query will be retrieved. It can return a group of text embeddings that relate or are similar to the query. A new prompt is then generated with the knowledge and is then sent to the LLM.
Now that we understand what Retrieval-Augmented Generation is, lets deploy and run through an example.
Example using PGVector and LLM
The example below is sourced from: https://github.com/rh-aiservices-bu/llm-on-openshift. It is slightly modified for this example and feel free to try out the other examples in the project. This example uses PGVector as the vector database and the Mistral-7B-Instruct-v0.2 model as the LLM (using GPU).
Let’s get started
Using the DEMO cluster
Create a new Data Science Project named rag-llm-demo.
Spin up a new Standard Data Science workbench.
Go into Openshift console and go to the rag-llm-demo namespace and deploy the resources below.
Deploy Vector Database
Postgresql Secret
kind: Secret
apiVersion: v1
metadata:
name: postgresql
stringData:
database-name: vectordb
database-password: vectordb
database-user: vectordb
type: OpaquePostgresql PVC
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: postgresql
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
volumeMode: FilesystemPostgresql Service
kind: Service
apiVersion: v1
metadata:
name: postgresql
spec:
selector:
app: postgresql
ports:
- name: postgresql
protocol: TCP
port: 5432
targetPort: 5432Postgresql Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgresql
spec:
strategy:
type: Recreate
recreateParams:
timeoutSeconds: 600
resources: {}
activeDeadlineSeconds: 21600
replicas: 1
selector:
matchLabels:
app: postgresql
template:
metadata:
labels:
app: postgresql
spec:
volumes:
- name: postgresql-data
persistentVolumeClaim:
claimName: postgresql
containers:
- resources:
limits:
memory: 512Mi
readinessProbe:
exec:
command:
- /usr/libexec/check-container
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
terminationMessagePath: /dev/termination-log
name: postgresql
livenessProbe:
exec:
command:
- /usr/libexec/check-container
- '--live'
initialDelaySeconds: 120
timeoutSeconds: 10
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
env:
- name: POSTGRESQL_USER
valueFrom:
secretKeyRef:
name: postgresql
key: database-user
- name: POSTGRESQL_PASSWORD
valueFrom:
secretKeyRef:
name: postgresql
key: database-password
- name: POSTGRESQL_DATABASE
valueFrom:
secretKeyRef:
name: postgresql
key: database-name
securityContext:
capabilities: {}
privileged: false
ports:
- containerPort: 5432
protocol: TCP
imagePullPolicy: IfNotPresent
volumeMounts:
- name: postgresql-data
mountPath: /var/lib/pgsql/data
terminationMessagePolicy: File
image: 'quay.io/rh-aiservices-bu/postgresql-15-pgvector-c9s:latest'
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
schedulerName: default-schedulerAfter applying all those files you should have a running PostgreSQL+pgvector server running, accessible at postgresql.rag-llm-demo.svc.cluster.local:5432 with credentials vectordb:vectordb.
The PgVector extension must be manually enabled in the server. This can only be done as a Superuser (above account won’t work). The easiest way is to:
-
Connect to the running server Pod, either through the Terminal view in the OpenShift Console, or through the CLI with:
oc rsh services/postgresql -
Once connected, enter the following command:
psql -d vectordb -c "CREATE EXTENSION vector;"(adapt the command if you changed the name of the database in the Secret).
If the command succeeds, it will print CREATE EXTENSION.
-
Exit the terminal
Deploy vLLM Mistral-7B-Instruct-v0.2
vLLM PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models-cache
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 40GivLLM Route
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: vllm
labels:
app: vllm
spec:
to:
kind: Service
name: vllm
weight: 100
port:
targetPort: http
tls:
termination: edge
wildcardPolicy: NonevLLM Service
kind: Service
apiVersion: v1
metadata:
name: vllm
labels:
app: vllm
spec:
clusterIP: None
ipFamilies:
- IPv4
ports:
- name: http
protocol: TCP
port: 8000
targetPort: http
type: ClusterIP
ipFamilyPolicy: SingleStack
sessionAffinity: None
selector:
app: vllmYou’ll need a HUGGING_FACE_HUB_TOKEN to download and use the LLM. You can get this by creating an account on Hugging Face and creating an access token in the https://huggingface.co/settings/tokens [Settings>Access Tokens] page. Insert your token in the env section.
Once logged in, you’ll also need to go to the model page on HuggingFace and agree to share your contact information to access the model.
vLLM Deployment
kind: Deployment
apiVersion: apps/v1
metadata:
name: vllm
labels:
app: vllm
spec:
replicas: 1
selector:
matchLabels:
app: vllm
template:
metadata:
creationTimestamp: null
labels:
app: vllm
spec:
restartPolicy: Always
schedulerName: default-scheduler
affinity: {}
terminationGracePeriodSeconds: 120
securityContext: {}
containers:
- resources:
limits:
cpu: '2'
memory: 8Gi
nvidia.com/gpu: '1'
requests:
cpu: '2'
readinessProbe:
httpGet:
path: /health
port: http
scheme: HTTP
timeoutSeconds: 5
periodSeconds: 30
successThreshold: 1
failureThreshold: 3
terminationMessagePath: /dev/termination-log
name: server
livenessProbe:
httpGet:
path: /health
port: http
scheme: HTTP
timeoutSeconds: 8
periodSeconds: 100
successThreshold: 1
failureThreshold: 3
env:
- name: HUGGING_FACE_HUB_TOKEN
value: 'CHANGEME'
args: [
"--model",
"mistralai/Mistral-7B-Instruct-v0.2",
"--download-dir",
"/models-cache",
"--dtype", "float16",
"--max-model-len", "6144" ]
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
allowPrivilegeEscalation: false
seccompProfile:
type: RuntimeDefault
ports:
- name: http
containerPort: 8000
protocol: TCP
imagePullPolicy: IfNotPresent
startupProbe:
httpGet:
path: /health
port: http
scheme: HTTP
timeoutSeconds: 1
periodSeconds: 30
successThreshold: 1
failureThreshold: 24
volumeMounts:
- name: models-cache
mountPath: /models-cache
- name: shm
mountPath: /dev/shm
terminationMessagePolicy: File
image: 'quay.io/rh-aiservices-bu/vllm-openai-ubi9:0.4.2'
volumes:
- name: models-cache
persistentVolumeClaim:
claimName: vllm-models-cache
- name: shm
emptyDir:
medium: Memory
sizeLimit: 1Gi
dnsPolicy: ClusterFirst
tolerations:
- key: nvidia-gpu-only
operator: Exists
effect: NoSchedule
strategy:
type: Recreate
revisionHistoryLimit: 10
progressDeadlineSeconds: 600| We are greatly reducing the amount of resources the LLM uses. |
Run through the Notebooks to test the LLM with RAG
Download and run through these 3 notebooks in your workbench:
or upload the repository to the workbench:
https://github.com/rh-aiservices-bu/llm-on-openshift.git
Creating an index and populating it with documents using PostgreSQL+pgvector
Depended on which workbench image you are using, we have to make some changes to the notebook.
-
Update the packages to install:
!pip install -q pgvector langchain-community pypdf sentence-transformers-
Update the Base Parameters and PostgreSQL info
product_version = 2.13
CONNECTION_STRING = "postgresql+psycopg://vectordb:vectordb@postgresql.rag-llm-demo.svc.cluster.local:5432/vectordb"
COLLECTION_NAME = f"rhoai-doc-{product_version}"Run through the notebook.
| Create the index and ingest the documents will take more than 5 minutes to complete |
Querying a PGVector index
-
Update the _Base Parameters and PostgreSQL info:
CONNECTION_STRING = "postgresql+psycopg://vectordb:vectordb@postgresql.rag-llm-demo.svc.cluster.local:5432/vectordb"
COLLECTION_NAME = "rhoai-doc-2.13"Run through the notebook
RAG example with Langchain, PostgreSQL+pgvector, and vLLM
# Replace values according to your vLLM deployment
INFERENCE_SERVER_URL = f"http://vllm.rag-llm-demo.svc.cluster.local:8000/v1"
MODEL_NAME = "mistralai/Mistral-7B-Instruct-v0.2"
MAX_TOKENS=1024
TOP_P=0.95
TEMPERATURE=0.01
PRESENCE_PENALTY=1.03
CONNECTION_STRING = "postgresql+psycopg://vectordb:vectordb@postgresql.rag-llm-demo.svc.cluster.local:5432/vectordb"
COLLECTION_NAME = "rhoai-doc-2.13"At the end, should have a successful RAG with LLM sample that you can query.
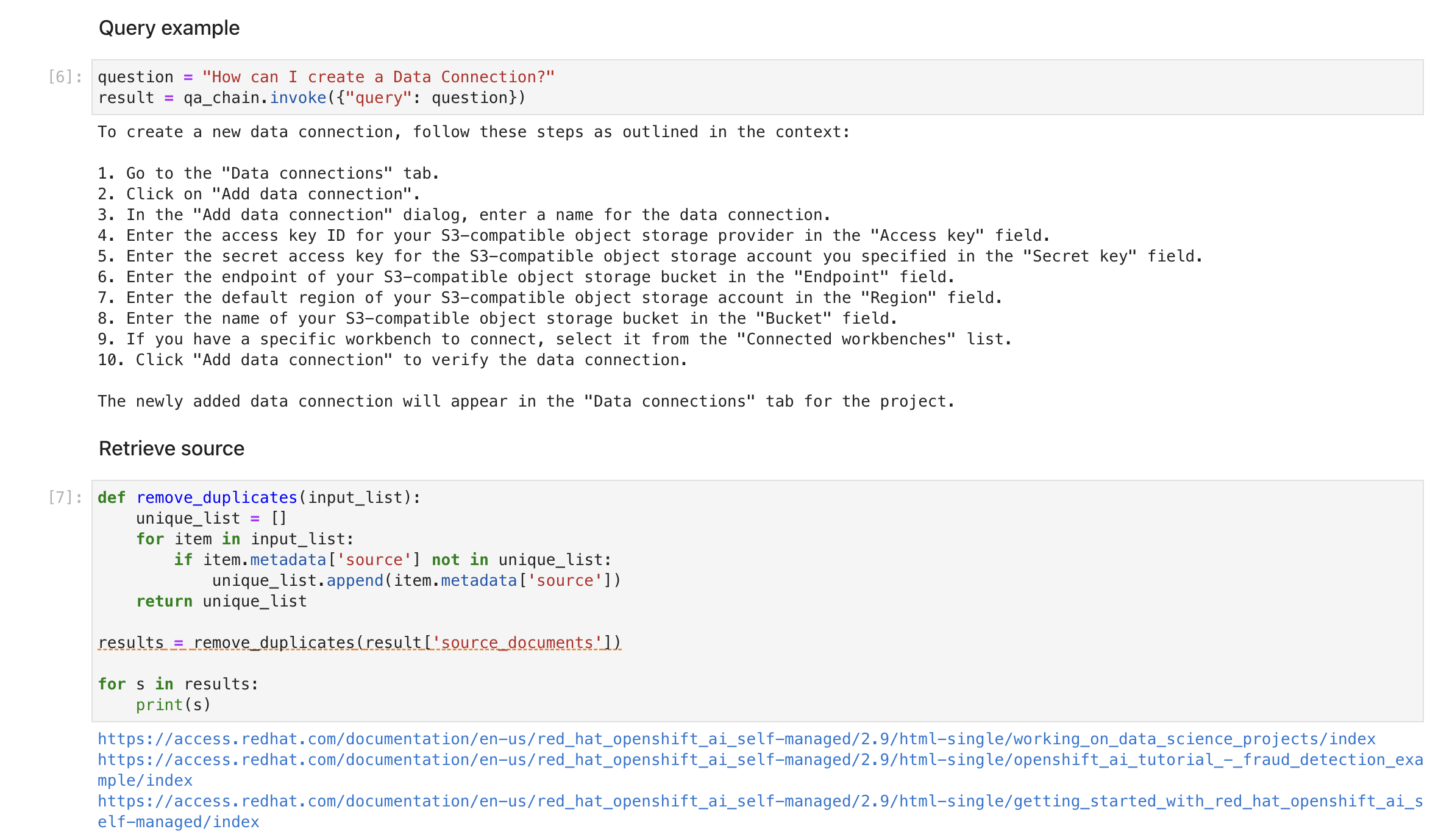
Run through the notebook to successfully demo an LLM with RAG using PGVector.
References
-
What is retrieval-augmented generation? - IBM Research Blog and Video describing the basics of RAG.