What is a Large Language Model?
A Large Language Model (LLM) is an instance of a foundation model. Foundation models are pre-trained on large amounts of unlabeled and self-supervised data. This means that the model learns from patterns in the data in a way that produces generalizable and adaptable output. LLMs are instances of foundation models applied specifically to text and text-like things (code).
Large language models are trained on large datasets of text, such as books, articles and conversations. These datasets can be extremely large. We’re talking petabytes of data. Training is the process of teaching the LLM to understand and generate language. It uses algorithms to learn patterns and predict what comes next. 1 Training an LLM with your data can help ensure that it can answer with the appropriate answer.
The term 'large' in LLM refers to the number of parameters in the model. These parameters are variables that the model uses to make predictions. The higher the number of parameters, the more detailed and nuanced the AI’s understanding of language can be. However, training such models requires considerable computational resources and specialized expertise. 2
There are many different types of LLMs for different use cases. Be sure to choose the appropriate one for you specific use case.
Explore LLMs
| As of Nov 22, 2024 the Node Feature Discovery and NVIDIA Operator appear to be broken on the latest version of OpenShift (4.17), be sure to use 4.16 when building a cluster so that the taints and tolerations work correctly. This may be fixed by Red Hat Engineering soon, so this warning can be removed when the operators are compatible with latest OCP. |
In the ai-accelerator project, there is an example of an LLM. Let’s look at the single-model-serving-tgis example.
This inference service uses flan-t5-small model.
The FLAN-T5 is a Large Language Model open sourced by Google under the Apache license at the end of 2022. We are using the small size which is 80 million parameters. FLAN-T5 models use the following models and techniques: the pretrained model T5 (Text-to-Text Transfer Transformer) and the FLAN (Finetuning Language Models) collection to do fine-tuning multiple tasks.
The model has been uploaded to minio S3 automatically when we ran the bootstrap script. The inference service uses the TGIS Standalone ServingRuntime for KServe and is not using a GPU.
Take a look at the InferenceService and the ServingRuntime resource in your Demo cluster.
Now let’s take a look at the single-model-serving-vllm example. This inference service uses IBM’s granite-3b-code-base model.
The Granite-3B-Code-Base-2K is a decoder-only code model designed for code generative tasks (e.g., code generation, code explanation, code fixing, etc.). It is trained from scratch with a two-phase training strategy. In phase 1, our model is trained on 4 trillion tokens sourced from 116 programming languages, ensuring a comprehensive understanding of programming languages and syntax. In phase 2, our model is trained on 500 billion tokens with a carefully designed mixture of high-quality data from code and natural language domains to improve the models’ ability to reason and follow instructions. Prominent enterprise use cases of LLMs in software engineering productivity include code generation, code explanation, code fixing, generating unit tests, generating documentation, addressing technical debt issues, vulnerability detection, code translation, and more. All Granite Code Base models, including the 3B parameter model, are able to handle these tasks as they were trained on a large amount of code data from 116 programming languages.
The Inference Service uses a vllm ServingRuntime which can be found here.
Nodes and Taints
Notice in the InferenceService of the vllm example there are GPU sections:
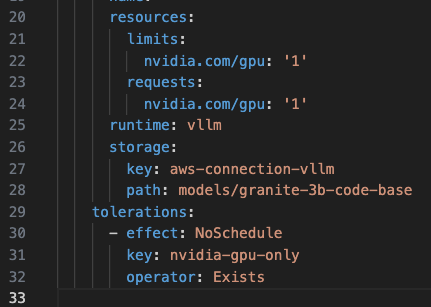
As you can see in the resources section, this Inference Service is needing a gpu to function properly.
You can also see that there is a toleration policy. When using the toleration on this resource, it is telling the cluster to deploy on a node that has a GPU attached to it so it can use it. It does this by using the toleration and a taint.
In this case, a node with a taint is a node with a GPU attached to it. The toleration has a key to validate against the taint. If it matches, the pod can run on the node.
Let’s take a look at the node:
In OpenShift Dashboard > Compute > Nodes we can see we have 3 nodes. Let’s look at the one with the gpu.
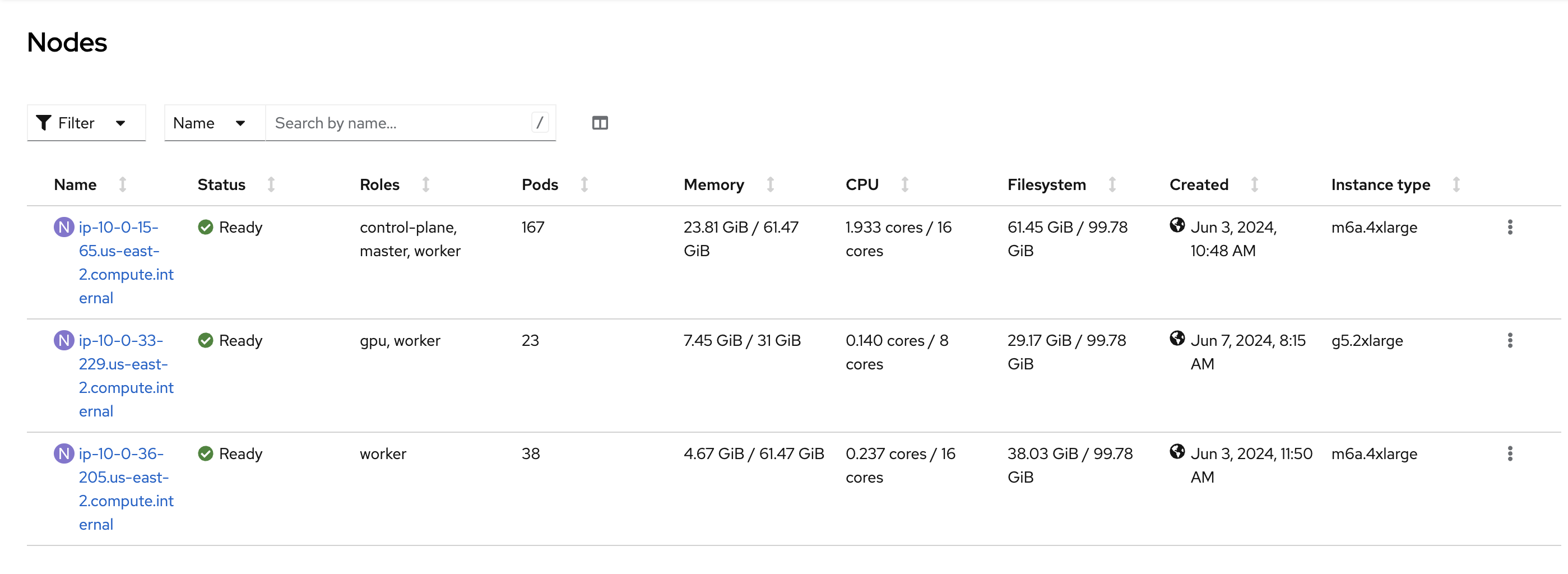
Select the GPU node. The instance is g5.2xlarge which has a gpu. You can see the different type of instances here: https://aws.amazon.com/ec2/instance-types/
If we look at the node details and scroll down we can see the taint that is has.

We can also see it in the yaml.
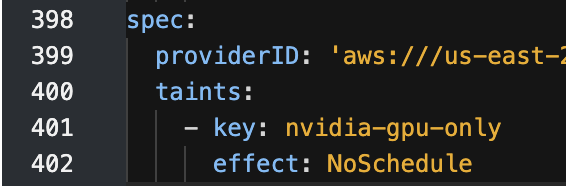
In the node yaml we can view the labels associated with the node. Lets look at the the nvidia.com/* labels. As you can see we have: nvidia.com/gpu.count: '1' which tells us that we have a gpu attached to this node

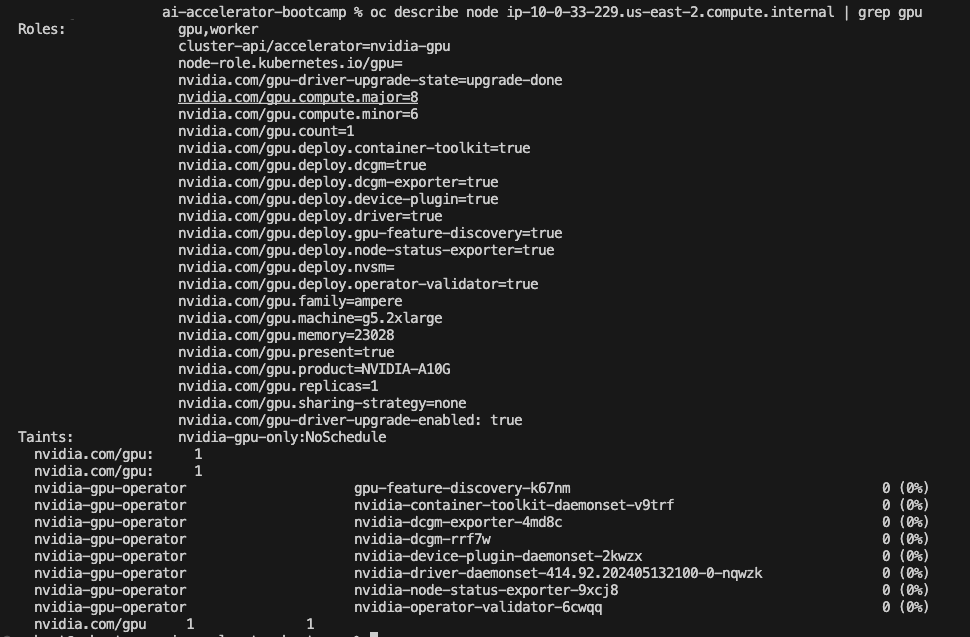
We can also run a oc describe` on the node:
oc describe node ip----**.us-east-2.compute.internal | grep gpu
Test Model Notebooks
After exploring the GPU Node details, open RHOAI and launch new workbench and run the tests for the LLMs. These can be found in the https://github.com/redhat-ai-services/ai-accelerator
-
tenants/ai-example/multi-model-serving/test
-
tenants/ai-example/single-model-serving-tgis/test
-
tenants/ai-example/single-model-serving-vllm/test
These are very simple tests to make sure that the InferenceService is working. View the logs of the inference service pod while you test.
References
-
https://www.run.ai/guides/machine-learning-engineering/llm-training
-
LLM Visualization - A peek "under the hood" showing what’s inside some common LLMs