Single Node, Multi-GPU vs Multi-Node, Multi-GPU vLLM
When deploying larger models, you will often need more than a single GPU to deploy the given model. vLLM provides the ability to consume multiple GPUs in a single node.
Additionally, vLLM can be used across multiple nodes, where vLLM uses a Ray backend.
| While multi-node vLLM does use Ray to distribute the model across multiple nodes, vLLM manages the Ray instance for you. The multi-node vLLM distribution does not depend on any external Ray instances or RHOAI’s distributed training tooling such as KubeRay or CodeFlare. |
Single Node, Multi-GPU
vLLM can consume additional GPUs available to the container using the --tensor-parallel-size flag, with the value equal to the number of GPUs available.
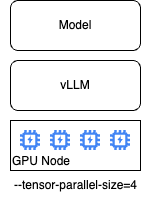
vLLM will automatically shard the model across the GPUs and expand the memory available for the KV Cache.
For more information on Tensor Parallelism see Tensor Parallelism.
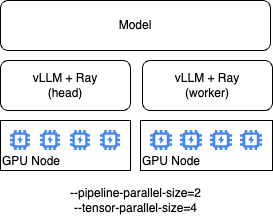
Multi-node vLLM
OpenShift AI includes a multi-node vLLM distribution that is currently Tech Preview.
| The vLLM image available from RHAIIS does not support multi-node model serving. If a customer is interested in multi-node model serving they must use OpenShift AI. |
Mutli-node vLLM deploys multiple vLLM containers that communicate with each other using Ray as the backend. When deploying a multi-node vLLM instance RHOAI will create a head vLLM pod that is responsible for managing the Ray cluster, and a number of worker pods equal to the --pipeline-parallel-size. In addition to managing the Ray cluster, the head vLLM pod is itself also a worker.
Each worker can also access multiple GPUs available to that node using --tensor-parallel-size.
Limitations of Multi-Node vLLM
Multi-node vLLM instances generally have worse performance compared to a single node equivalent due to the network being a bottleneck.
For example, a model deployed on a single node with 8 GPUs will have better performance than a multi-node instance with two nodes where each node has 4 GPUs.
Some of these limitations can be overcome with high speed networking such as Infiniband, but it is always recommended to utilize single node instances whenever possible.
Sharding Considerations
Models cannot be sharded across an arbitrary number of GPUs. The model itself needs to be devisable by the total number of GPUs. Generally the num_attention_heads is the key characteristic that is required to be devisable by the total number of GPUs. The num_attention_heads can generally be found in the models config.json file
For example, Granite 3.3 8b Instruct has 32 attention heads. This means that the model can be sharded by any number of GPUs that 32 is devisable by, such as 2, 4, or 8 GPUs. However, the model cannot be deployed with 3 GPUs.
Some models such as Mixture of Expert (MoE) models such as Llama 4, approach sharding the model in a different manner and may not have the same limitations.