Tensor Parallelism
Overview
As large language models continue to grow in size and complexity, they often exceed the memory capacity of a single GPU. Tensor parallelism is a distributed computing technique that addresses this challenge by sharding model weights across multiple GPUs, enabling concurrent computation for reduced latency and enhanced scalability.
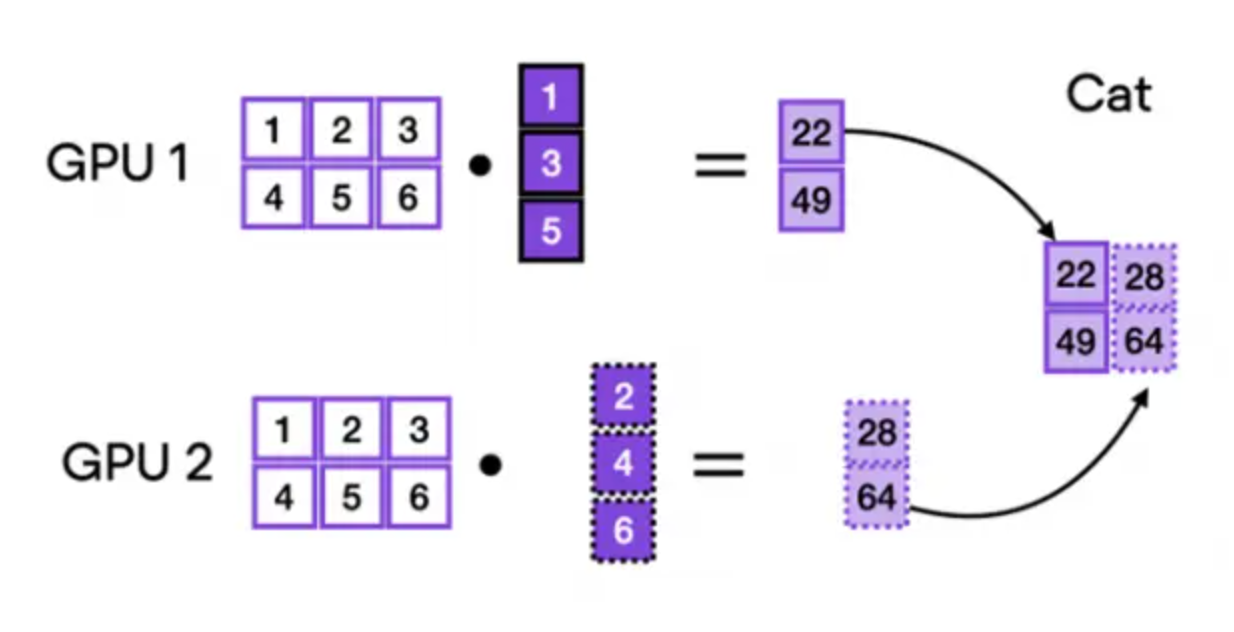
In tensor parallelism, each GPU processes a slice of a tensor and only aggregates the full tensor when necessary for specific operations. This approach allows larger models to run efficiently across multiple devices while maintaining performance.
How Tensor Parallelism Works
The core principle involves splitting weight matrices strategically:
-
Column-wise splitting: Weight tensors are divided along columns, with each GPU processing its portion of the matrix multiplication
-
Result aggregation: Individual GPU outputs are concatenated or summed to reconstruct the final result
-
Minimal communication: GPUs only need to communicate when aggregating results, reducing overhead
For example, during matrix multiplication with the first weight tensor, the computation is distributed by splitting the weight tensor column-wise. Each GPU multiplies its assigned columns with the input, and the separate outputs are then concatenated to produce the final result.
Tensor Parallelism in vLLM
vLLM implements tensor parallelism techniques originally developed for training in Megatron-LM (Shoeybi et al., 2019), but optimized specifically for inference workloads. This adaptation addresses the unique requirements of serving large language models in production environments.

Implementation Techniques
Tensor parallelism relies on two primary techniques for distributing computations:
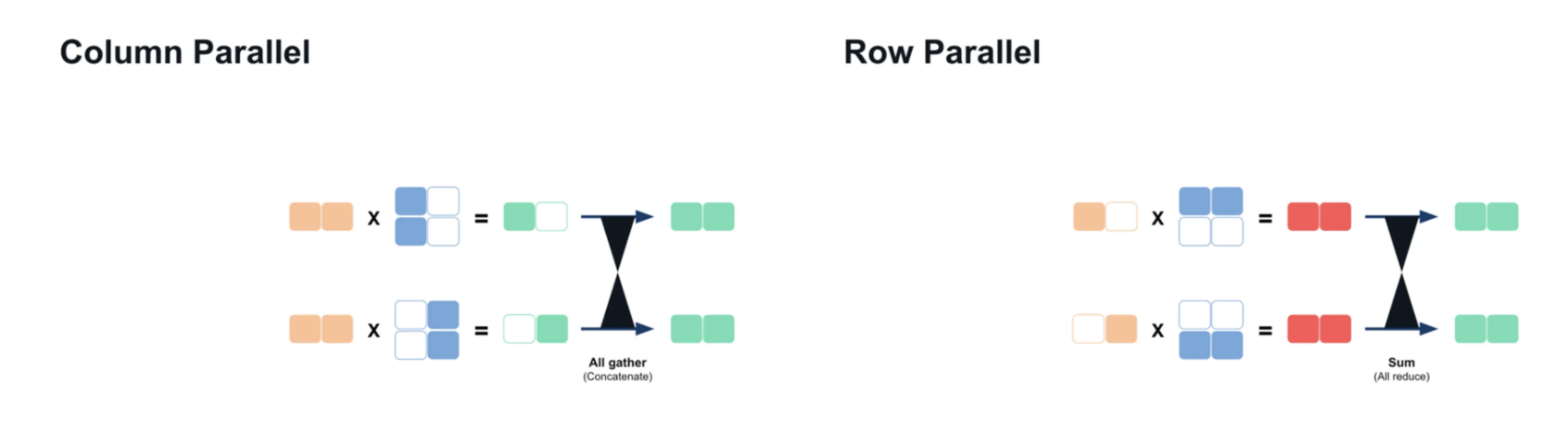
- Column Parallelism
-
Weight matrices are split along columns, with each GPU processing its assigned portion. Results are concatenated after computation to reconstruct the full output.
- Row Parallelism
-
Matrices are split along rows, with each GPU computing partial results. An all-reduce operation sums these partial results to produce the final output.
Performance Benefits
Tensor parallelism delivers significant performance improvements by:
-
Memory bandwidth multiplication: Multiple GPUs access memory in parallel, eliminating single-GPU bottlenecks
-
Latency reduction: Distributed computation reduces time-to-first-token and overall inference latency
-
Scalability: Larger models can be served that would otherwise be impossible on single devices