GPU Aggregation
GPU Aggregation Overview
Compute workloads can benefit from using separate GPU partitions. The flexibility of GPU partitioning allows a single GPU to be shared and used by small, medium, and large-sized workloads. GPU partitions can be a valid option for executing Deep Learning workloads. An example is Deep Learning training and inferencing workflows, which utilize smaller datasets but are highly dependent on the size of the data/model, and users may need to decrease batch sizes.
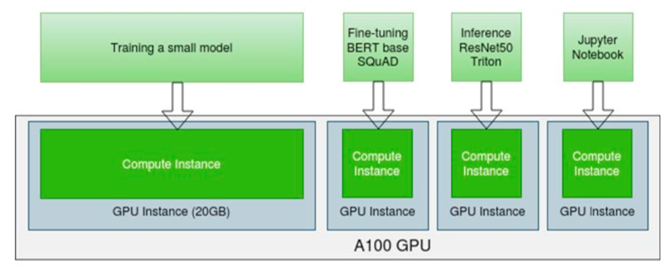
Why GPU Aggregation?
Some Large Language Models (LLMs), such as Llama-3-70B and Falcon 180B, can be too large to fit into the memory of a single GPU (vRAM). Or in some cases, GPUs that would be large-enough might be difficult to obtain. If you find yourself in such a situation, it is natural to wonder whether an aggregation of multiple, smaller GPUs can be used instead of one single large GPU.
Thankfully, the answer is essentially Yes. To address these challenges, we can use more advanced configurations to distribute the LLM workload across several GPUs. One option is leveraging tensor parallelism, where the LLM is split across several GPUs, with each GPU processing a portion of the model’s tensors. This approach ensures efficient utilization of available resources (GPUs) across one or several workers.
Some Serving Runtimes, such as vLLM, support tensor parallelism, allowing for both single-worker and multi-worker configurations (the difference whether your GPUs are all in the same machine, or are spread across machines).