Expert Parallelism
Overview
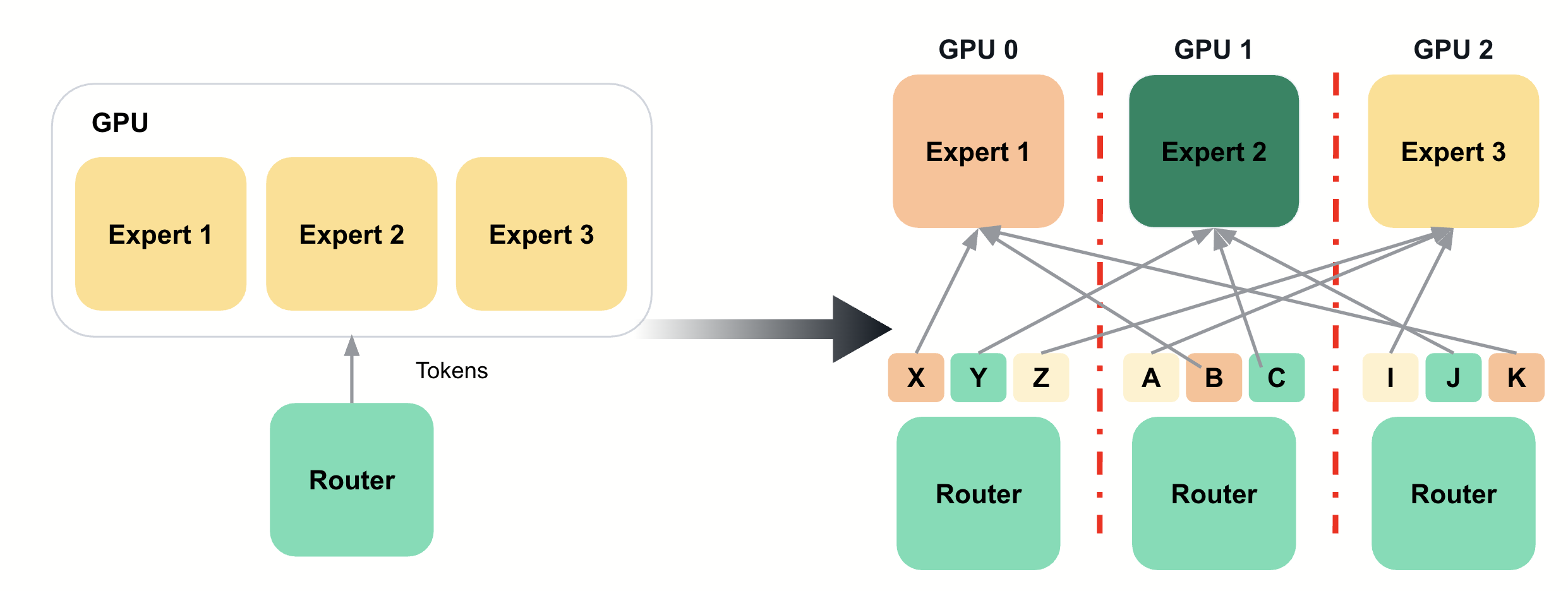
Expert parallelism is a specialized distributed computing technique designed specifically for Mixture of Experts (MoE) models. Unlike traditional parallelism strategies that distribute computation across all model parameters, expert parallelism leverages the sparse activation pattern of MoE architectures where only a subset of experts are activated for each input token.
This approach assigns dedicated GPUs to specific expert networks, enabling efficient scaling of large MoE models while maintaining computational efficiency. Expert parallelism is particularly effective because it aligns the hardware distribution with the model’s inherent sparsity, avoiding the communication overhead that would occur if experts were distributed across multiple devices.
How Expert Parallelism Works
The core principle revolves around the sparse activation pattern of MoE models:
-
Expert assignment: Each GPU is assigned one or more complete expert networks
-
Selective activation: Only the experts chosen by the router are activated for each token
-
Token routing: Input tokens are routed to the appropriate GPUs based on expert selection
-
Result aggregation: Outputs from activated experts are combined according to the router’s weights
For example, in a model with 8 experts distributed across 4 GPUs (2 experts per GPU), each input token activates only 2 experts. The router determines which experts to use, and only those specific GPUs perform computation while others remain idle for that token.
Mixture of Experts (MoE) Models
MoE models represent a fundamental shift in neural network architecture, replacing dense feed-forward networks with sparse expert networks. This architecture enables scaling model capacity without proportionally increasing computational costs.
MoE Architecture Components
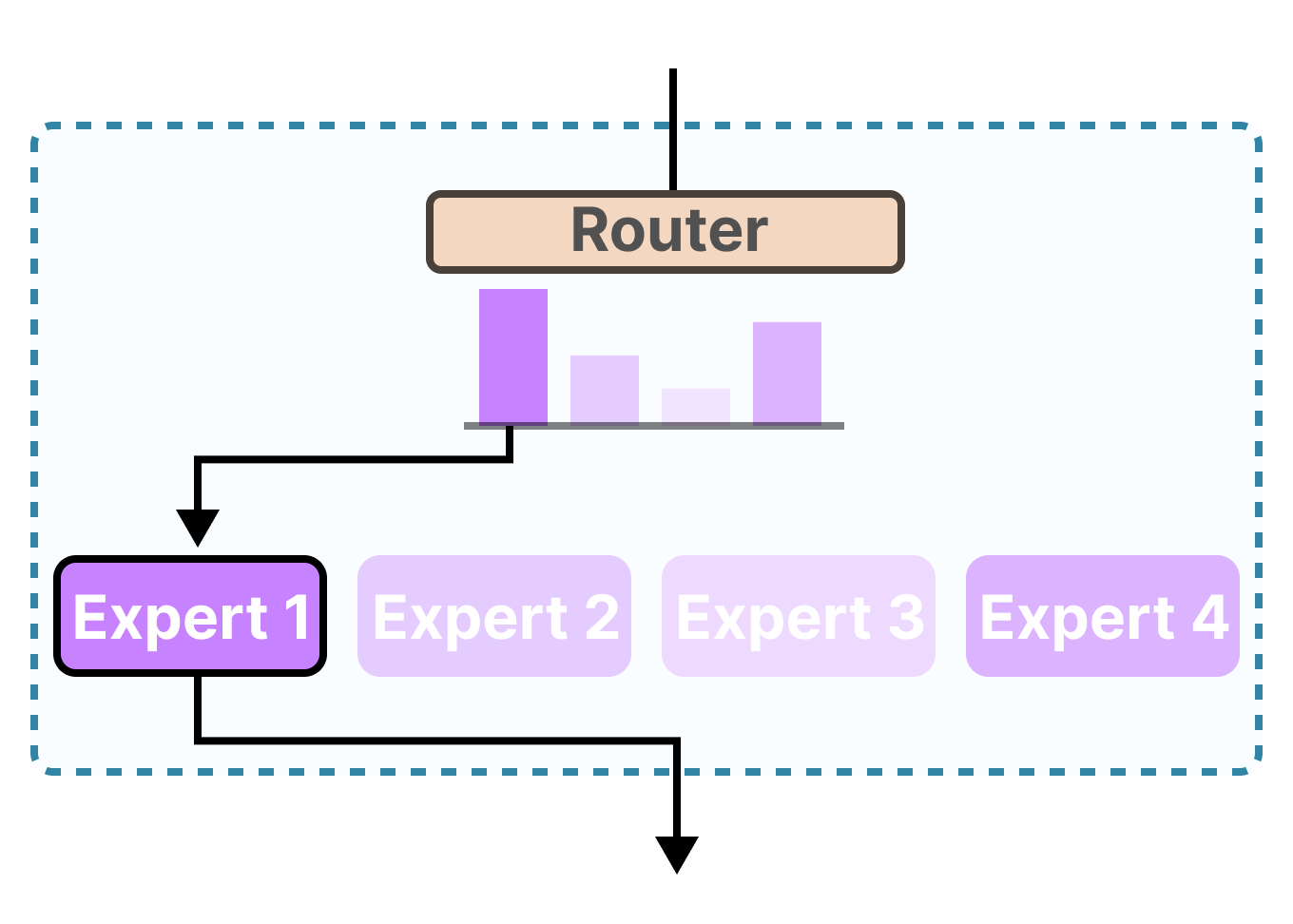
- Router Network
-
A learned gating mechanism that determines which experts should process each input token. The router typically selects the top-k experts based on input features and assigns mixing weights.
- Expert Networks
-
Specialized sub-networks (usually feed-forward networks) that process specific types of inputs. Each expert develops specialized knowledge for particular input patterns or domains.
- Load Balancing
-
Mechanisms to ensure experts are utilized evenly, preventing some experts from being overused while others remain underutilized.
Sparse Activation Benefits
MoE models achieve significant advantages through sparse activation:
-
Parameter efficiency: Large model capacity with controlled computational cost
-
Specialization: Experts can specialize in specific domains or input types
-
Scalability: Model capacity scales with the number of experts without linear computational increase
-
Flexibility: Different experts can be activated for different inputs, enabling adaptive computation
Expert Parallelism in vLLM
vLLM implements expert parallelism with optimizations specifically designed for inference workloads and efficient GPU utilization.
Implementation Techniques
- Static Expert Assignment
-
vLLM assigns experts to GPUs at initialization time based on model configuration and available hardware. This static assignment eliminates dynamic routing overhead during inference.
- Token-level Routing
-
Individual tokens are routed to appropriate expert GPUs based on router decisions. This fine-grained routing enables optimal expert utilization.
- Batched Expert Execution
-
Tokens routed to the same expert are batched together to maximize GPU utilization and reduce kernel launch overhead.
- Communication Optimization
-
vLLM minimizes inter-GPU communication by only transferring tokens and gradients between GPUs that host the selected experts.
Hardware Requirements
Expert parallelism has specific hardware considerations:
- GPU Distribution
-
-
Balanced allocation: Each GPU should have similar computational capacity for expert hosting
-
Memory requirements: Sufficient memory per GPU to store assigned experts
-
Communication bandwidth: Adequate interconnect for token routing and result aggregation
-
- Network Topology
-
-
All-to-all communication: Efficient routing requires good connectivity between all expert GPUs
-
Low latency: Fast token routing is crucial for maintaining inference performance
-
Bandwidth scaling: Network bandwidth should scale with the number of experts
-
When to Use Expert Parallelism
Expert parallelism is most effective when:
-
MoE model architecture: Specifically designed for Mixture of Experts models
-
Large expert count: Models with many experts benefit from distribution across GPUs
-
Sparse activation patterns: Input patterns that naturally lead to sparse expert usage
-
Sufficient hardware: Enough GPUs to distribute experts effectively
-
Balanced workloads: Applications where expert usage is relatively balanced
Combining Expert Parallelism with Other Strategies
Expert parallelism can be combined with other parallelism techniques for optimal performance:
- Expert + Tensor Parallelism
-
-
Each expert can be further distributed using tensor parallelism
-
Useful for very large individual experts
-
Requires careful communication optimization
-
- Expert + Pipeline Parallelism
-
-
Expert layers can be part of pipeline stages
-
Enables scaling both model depth and expert count
-
Complex routing across pipeline stages
-
- Hybrid Approaches
-
-
Combine multiple parallelism strategies based on model architecture
-
Optimize for specific hardware configurations
-
Balance between different performance objectives
-
# 16 GPUs, 8 experts, 2 GPUs per expert (tensor parallelism within experts) expert_parallel_size = 8 tensor_parallel_size = 2 experts_per_gpu = 1