Pipeline Parallelism
Overview
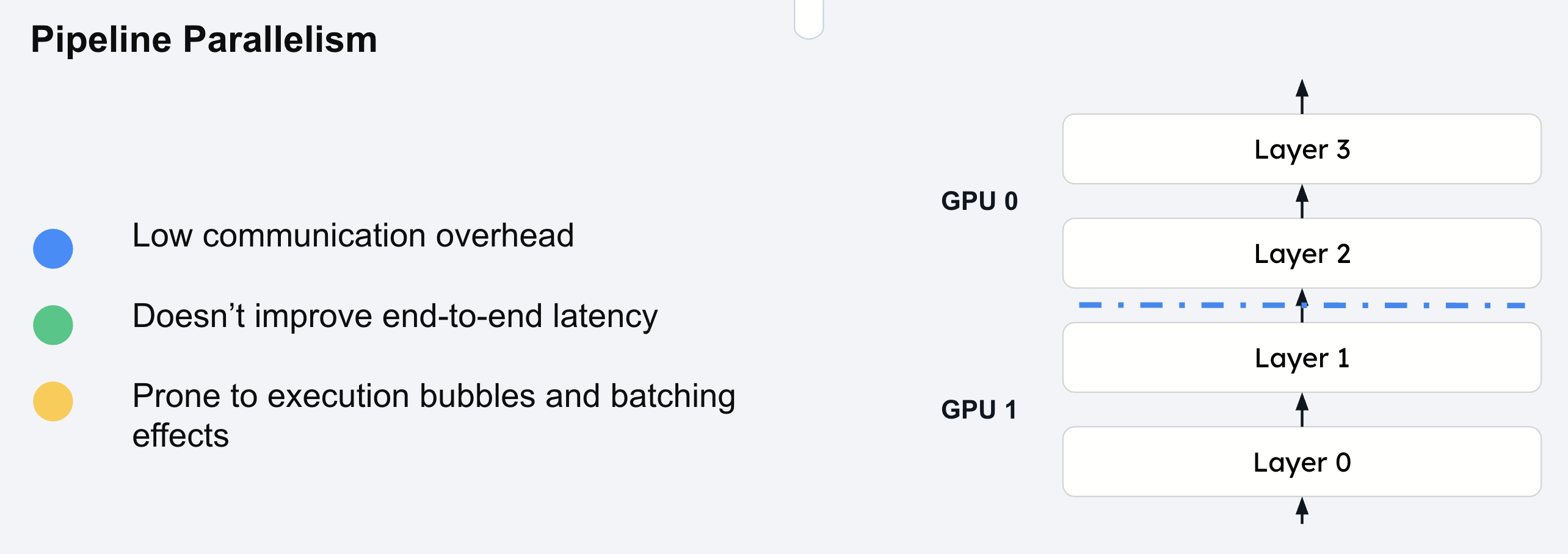
When models become so large that they exceed the memory capacity of multiple GPUs within a single node, pipeline parallelism provides a solution for distributed inference across multiple nodes. This technique partitions the model into sequential stages, with each stage containing contiguous layers that are processed by different GPUs or nodes.
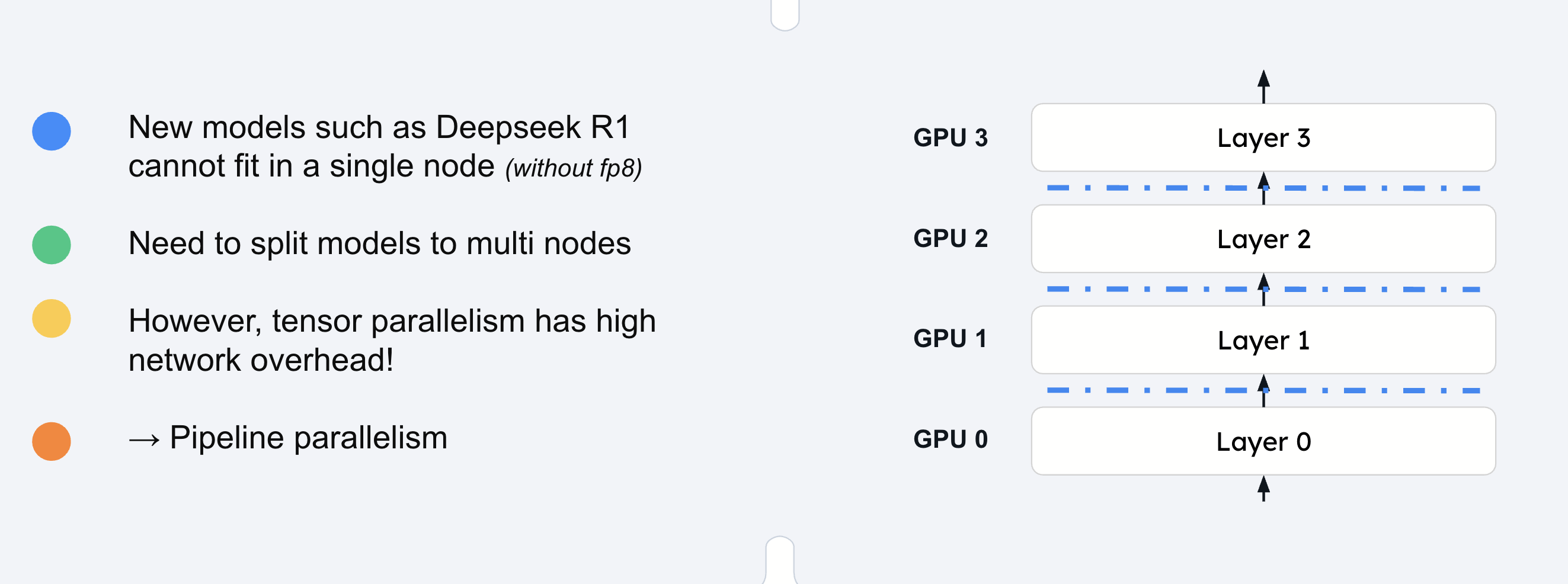
Pipeline parallelism differs from tensor parallelism in that it splits the model vertically (across layers) rather than horizontally (across tensor dimensions). Each GPU or node in the pipeline processes a complete subset of the model’s layers, making it particularly effective for extremely large models like DeepSeek R1 or Llama 3.1 405B that cannot fit on a single node.
How Pipeline Parallelism Works
The core principle involves sequential processing through model stages:
-
Layer partitioning: The model is divided into contiguous blocks of layers, with each stage assigned to a different GPU or node
-
Sequential processing: Input flows through stages sequentially, with each stage processing its assigned layers
-
Activation passing: Intermediate activations are transmitted between stages as computation progresses
-
Minimal communication: Data transfer occurs only between adjacent pipeline stages, reducing overall communication overhead
For example, in a 4-stage pipeline, Stage 1 processes layers 1-8, Stage 2 processes layers 9-16, and so on. Each stage completes its computation before passing activations to the next stage in the pipeline.
Pipeline Parallelism in vLLM
vLLM implements pipeline parallelism with advanced scheduling optimizations to address the inherent challenges of sequential processing. Unlike tensor parallelism, which can reduce latency through parallel computation, pipeline parallelism focuses on enabling deployment of models that would otherwise be impossible to serve.
Implementation Techniques
Pipeline parallelism in vLLM uses sophisticated scheduling strategies to maximize throughput:
- Micro-batch Processing
-
Instead of processing one request at a time, vLLM processes multiple micro-batches simultaneously across different pipeline stages. This keeps all GPUs active and improves overall throughput.
- Asynchronous Execution
-
Pipeline stages operate asynchronously, allowing multiple requests to be processed concurrently at different stages. This reduces pipeline bubbles and idle time.
- Dynamic Load Balancing
-
vLLM automatically adjusts the number of layers per stage based on computational complexity and memory requirements to optimize performance across the pipeline.
Performance Characteristics
Pipeline parallelism provides different performance trade-offs compared to tensor parallelism:
- Memory Efficiency
-
-
Reduced per-GPU memory: Each GPU only stores a subset of model layers
-
Scalability: Enables serving models that exceed single-node memory capacity
-
Linear scaling: Memory requirements scale linearly with the number of pipeline stages
-
- Throughput Optimization
-
-
Batch processing: Higher throughput achieved through micro-batch scheduling
-
Pipeline utilization: Advanced scheduling keeps all stages busy
-
Communication efficiency: Lower communication overhead compared to tensor parallelism
-
- Latency Considerations
-
-
Sequential processing: Inherently higher latency than tensor parallelism due to sequential stage execution
-
Pipeline depth: Deeper pipelines increase latency but enable larger models
-
Micro-batch trade-offs: Smaller micro-batches reduce latency but may decrease throughput
-
Hardware Requirements
Pipeline parallelism has different networking requirements compared to tensor parallelism:
- Inter-node Communication
-
-
Lower bandwidth requirements: Only adjacent stages communicate, reducing network pressure
-
Ethernet compatibility: Can work effectively with standard Ethernet connections
-
Reduced communication frequency: Data transfer occurs once per pipeline stage
-
- Node Configuration
-
-
Homogeneous nodes: Each pipeline stage should have similar computational capacity
-
Memory distribution: Memory requirements are distributed across nodes
-
Storage considerations: Model weights are distributed, reducing per-node storage needs
-
When to Use Pipeline Parallelism
Pipeline parallelism is most effective when:
-
Model size exceeds node capacity: Required for models that cannot fit on a single node even with tensor parallelism
-
Multi-node deployment: Available infrastructure spans multiple nodes
-
Throughput priority: Batch processing throughput is more important than individual request latency
-
Limited high-bandwidth interconnects: When NVLink or InfiniBand are not available between nodes
Combining Pipeline and Tensor Parallelism
For optimal performance with extremely large models, vLLM supports combining both parallelism strategies:
-
Tensor parallelism within nodes: Distribute layers across GPUs within each node
-
Pipeline parallelism across nodes: Distribute layer groups across multiple nodes
-
Hybrid scaling: Achieve maximum model capacity and performance through combined approaches
# 8 nodes, 8 GPUs per node, 64 total GPUs tensor_parallel_size = 8 # GPUs per node pipeline_parallel_size = 8 # Number of nodes
Distributed Runtime Management
vLLM supports distributed tensor-parallel and pipeline-parallel inference through flexible runtime management systems. The framework implements Megatron-LM’s tensor parallel algorithm and provides multiple execution backends to handle distributed coordination.
Execution Backends
vLLM manages distributed runtime using two primary execution backends:
- Multiprocessing Backend
-
Python’s native multiprocessing is used for single-node deployments when sufficient GPUs are available on the same node. This backend provides:
-
Lower overhead for single-node scenarios
-
No external dependencies beyond Python standard library
-
Automatic selection when conditions are met
-
Optimal for tensor parallelism within a single node
-
- Ray Backend
-
Ray is used for multi-node inference and complex distributed scenarios. This backend enables:
-
Multi-node multi-GPU deployments
-
Advanced scheduling and resource management
-
Fault tolerance and dynamic scaling
-
Required for pipeline parallelism across nodes
-
Backend Selection Logic
vLLM automatically selects the appropriate backend based on deployment configuration:
- Default Behavior
-
-
Multiprocessing: Used when not running in a Ray placement group and sufficient GPUs are available on the same node for the configured
tensor_parallel_size -
Ray: Used for multi-node deployments or when multiprocessing conditions are not met
-
- Manual Override
-
The default backend selection can be overridden using:
-
LLMclass:distributed_executor_backendargument -
API server:
--distributed-executor-backendargument -
Values:
mpfor multiprocessing,rayfor Ray
-