Understanding the Key Evaluation Metrics
Performance Metrics (Latency and Throughput)
Time to first token (TTFT)
Measuring the time taken for the LLM to output the first generated token to the user.
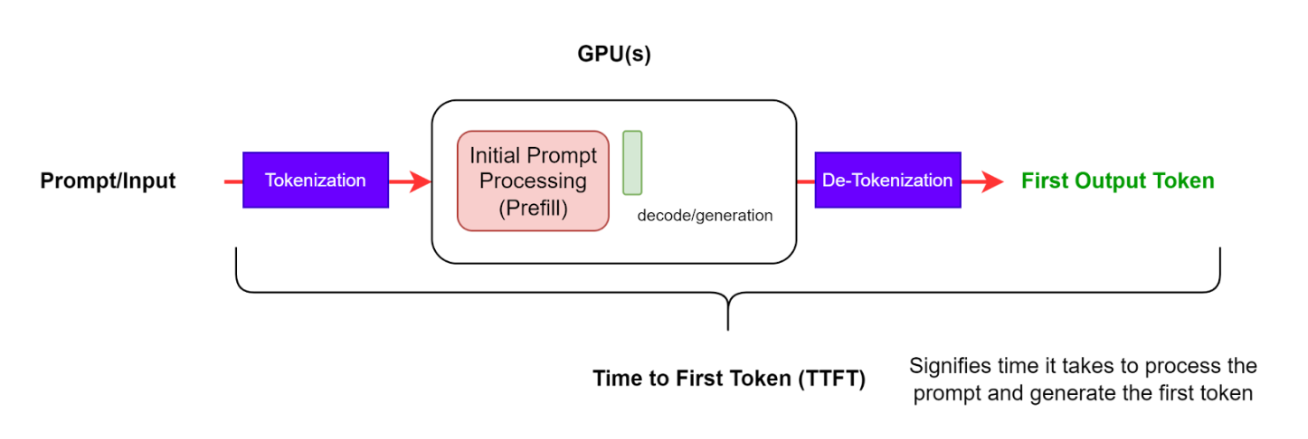
Why it matters: * It’s the most user-visible latency metric—especially important for chatbots, co-pilots, and interactive tools. * High TTFT makes apps feel sluggish, even if generation speed is fast afterward.
vLLM tuning: * PagedAttention and continuous batching in vLLM help lower TTFT by enabling fast context processing and overlapping prefill/decode steps. * Speculative decoding can reduce TTFT by using a small draft model to “guess” tokens ahead of time. * Prefix caching reduces TTFT significantly for repeated prompts or system instructions. * TTFT can increase under high concurrency if scheduler queueing delays prefill.
Time per output token (TPOT)
Measuring the average latency between two subsequent generated tokens.
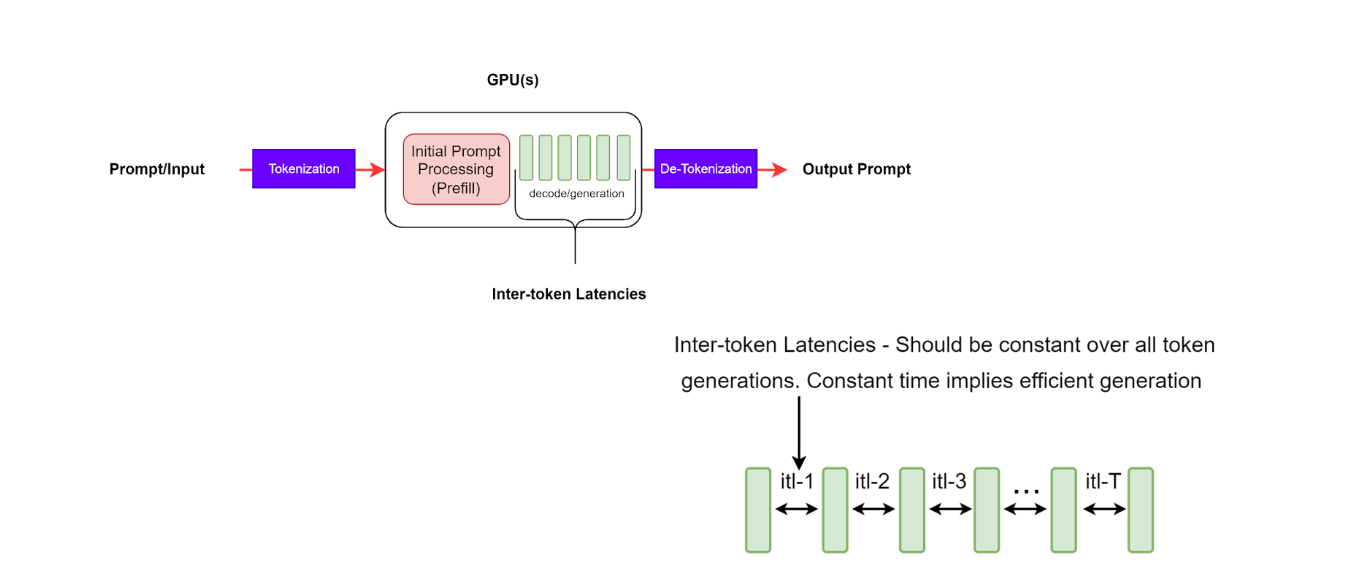
Why it matters: * Critical for streaming use cases like code assistants, real-time summarization, and chat. * Lower TPOT improves perceived responsiveness, especially with longer outputs.
vLLM tuning: * Batching tokens across requests helps maximize GPU throughput but may slightly increase TPOT for individual users. * Speculative decoding lowers TPOT by computing multiple tokens per decoding step. * Use low-latency quantized models (e.g. INT8) to reduce compute per token. * Monitor GPU saturation — if compute is maxed out, TPOT increases.
Token per second (TPS)
Total TPS per system represents the total output tokens per seconds throughput across all concurrent requests.
Why it matters: * Represents raw throughput of the system. * High TPS = better scaling under load and lower infrastructure cost per request.
vLLM tuning: * Tensor parallelism allows larger models to be split across multiple GPUs, increasing TPS. * PagedAttention enables efficient multi-request execution to maximize GPU usage. * Chunked prefill and smart scheduler design reduce wasted compute cycles. * Use GPU-efficient models (e.g., LLaMA-2 over GPT-J) for higher TPS on constrained hardware.
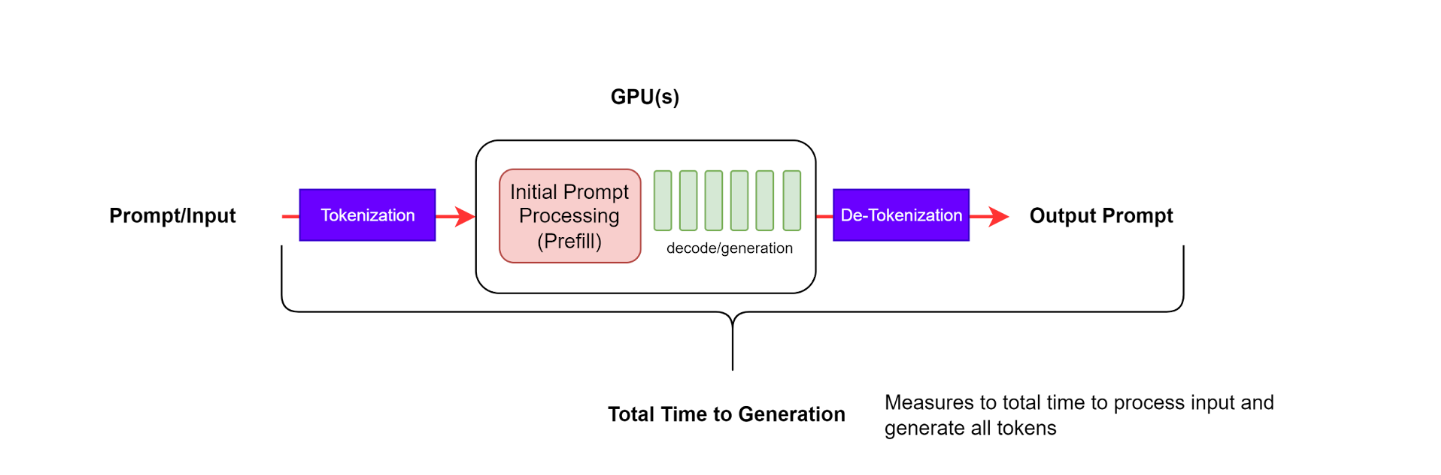
End-to-End Request Latency
Indicates how long it takes from submitting a query to receiving the full response, including the performance of your queueing/batching mechanisms and network latencies
Why it matters: * Most complete measure of user experience — not just model speed but system responsiveness. * Can uncover hidden bottlenecks (e.g., slow tokenization, network hops, or cold starts).
vLLM tuning: * Scheduler delays can spike latency during high traffic — monitor queue lengths. * Prefix caching reduces compute for repeated prompts. * Ensure fast tokenizer loading and model warm-up (especially on cold start). * Avoid container cold starts and autoscaling lag in production deployments.
Goodput
Goodput is a measure of how many requests per second a system can serve while meeting latency targets such as:
-
TTFT (Time to First Token) < x ms
-
TPOT (Time per output token) < Y ms
-
Measured at P90 or higher percentiles
Why it matters: * Aligns infrastructure performance with user-facing SLAs. * Helps evaluate whether a system is performant and predictable under real-world conditions.
vLLM tuning: * Batching and scheduling must balance throughput vs. SLA guarantees. * Tune token budget allocation per engine step to minimize TTFT spikes. * Use smaller models or quantized versions when SLAs aren’t met with a given hardware profile. * Monitor prefix cache hit rate and KV reuse to reduce redundant compute. * Load test using tools like GuideLLM to measure P95/P99 goodput under stress.
P95/P99
Measures the time it takes for 95% / 99% of requests to complete and helps to identify performance outliers.
Why it matters: * Many enterprise SLAs are defined at these thresholds. High P99 latency can indicate issues under high load or with long prompts.
vLLM tuning: * Can be improved by enabling continuous batching, adjusting block size, and optimizing KV cache memory use.
Latency jitter
-
Variation in response time for similar requests
Why it matters: * Affects user experience, especially in chat or streaming types of use cases.
vLLM tuning: * Tuning scheduling, prefill/decode ratios, or avoiding memory fragmentation.
Quality and Accuracy Metrics
Quality and accuracy metrics work towards determining how accurate or helpful a model is in its responses. Includes factual correctness and reasoning ability.
vLLM does not directly impact base model quality but it can degrade the model performance with poor quantization or misaligned sampling settings (e.g. temperature).
Task-based benchmarks
E.g. MMLU, HellaSwag, TruthfulQA
-
Use the lm-eval-harness benchmark framework to benchmark supported models.
Why it matters: * Helps compare models on known evaluation sets.
vLLM tuning: * Ensure benchmark setup matches the sampling strategy used in production.
Prompt-type sensitivity
Measures how performance varies across task types like coding, summarization, math, etc.
Why it matters: * Some models excel at code but underperform at reasoning or language generation.
vLLM tuning: * Use GuideLLM with varied prompt templates to evaluate model strengths and weaknesses in deployed context.
Fine-Tuned Response Accuracy
Measures how well fine-tuned models reflect intended style, tone, or accuracy based on private enterprise data.
Why it matters: * Enterprise RAG or fine-tuned models must reflect business needs.
vLLM tuning: * Ensure quantization and sampling configs don’t interfere with expected accuracy or tone.
Output quality
Measure whether the model completes tasks as prompted and avoids generating incorrect or fabricated information.
Why it matters: * Hallucination is a major blocker for enterprise GenAI adoption.
Measurement: * Use RAGAS, GuideLLM evals, or human-reviewed scoring based on instruction compliance.
vLLM tuning: * Adjust temperature/top-p/top-k to reduce variability and hallucination risk; ensure alignment tuning or RAG is respected.
Instruction-following, hallucination rate
Measures whether the model completes tasks as prompted and avoids hallucination.
Why it matters: * Hallucination is a major blocker for enterprise Gen AI adoption.
Measurement: * Use RAGAS, GuideLLM evals, or human-reviewed scoring based on instruction compliance.
vLLM tuning: * Adjust temperature/top-p/top-k to reduce variability and hallucination risk; ensure alignment tuning or RAG is respected.
System / Infrastructure Metrics
KV Cache hit rate
How often previously computed tokens are reused from cache.
Why It Matters: * High hit rates reduce computation cost and first-token latency.
vLLM Tuning: * Use prefix caching (enabled by default in v1 engine) and optimize block allocation strategies.
Memory utilization (VRAM/CPU)
Measures how efficiently GPU/CPU memory is used during inference.
Why It Matters: * Underutilized memory = wasted resources; over-utilized = OOM errors.
vLLM Tuning: * Monitor --max-model-len, use quantized models, and choose appropriate block size.
Concurrency/max request capacity
How many simultaneous requests a system can handle.
Why It Matters: * Determines throughput and scalability.
vLLM Tuning: * vLLM’s continuous batching, paged KV attention, and memory reuse allow high concurrency when properly tuned.
Failure rate
How often inference requests fail due to system errors, OOMs, or timeouts.
Why It Matters: * Impacts reliability and uptime.
vLLM Tuning: * Can be reduced with autoscaling, appropriate memory sizing, watchdogs, and quantization.
Cost per token/request
-
Measures how much it costs to generate a response (in infra terms).
Why It Matters: * Enterprises need to tie GenAI usage to ROI.
vLLM Tuning: Improve via: quantization (INT8, FP8), batching, block reuse. GuideLLM can be used to compare cost impact across sampling configs or model choices.