LLM Compressor: Model Comparison Examples
Overview
This guide provides real-world examples of memory and hardware savings achieved through Red Hat AI’s compressed model collection. These examples demonstrate the practical impact of deploying compressed models versus original versions.
Companion to: LLM Compressor Executive Guide
Example 1: Mistral Small 24B - FP8 Compression
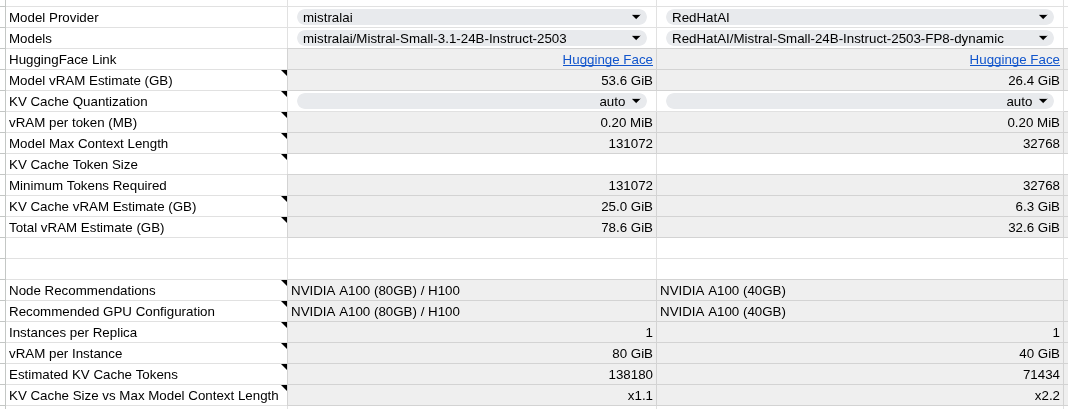
Business Impact: * 50% memory reduction (53.6 GiB → 26.4 GiB) enables deployment on smaller GPU configurations * Cost savings from using A100 40GB instead of A100 80GB * Same model capabilities with FP8 precision optimization
Example 2: DeepSeek R1 14B - W4A16 Quantization
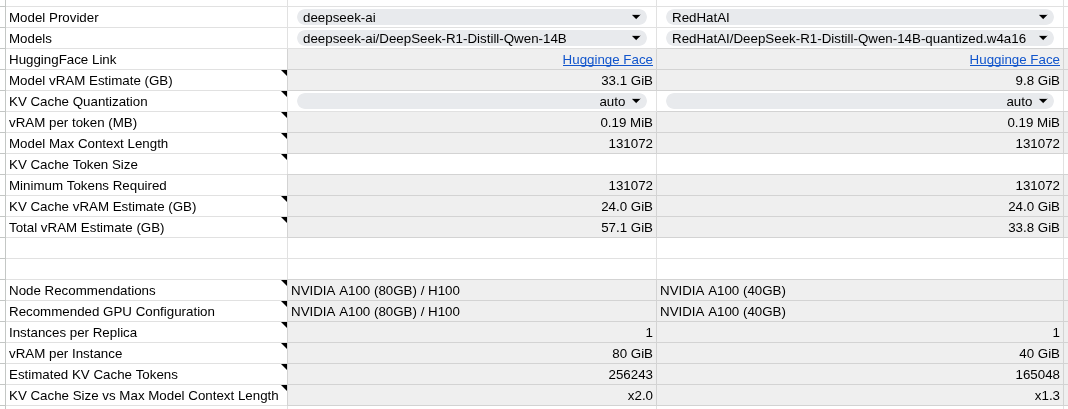
Business Impact: * 70% memory reduction (33.1 GiB → 9.8 GiB) through aggressive W4A16 quantization * Deployment flexibility fits on much smaller GPU configurations * Evaluation required due to aggressive compression level
Example 3: Llama 3.2 90B Vision - FP8 Multimodal
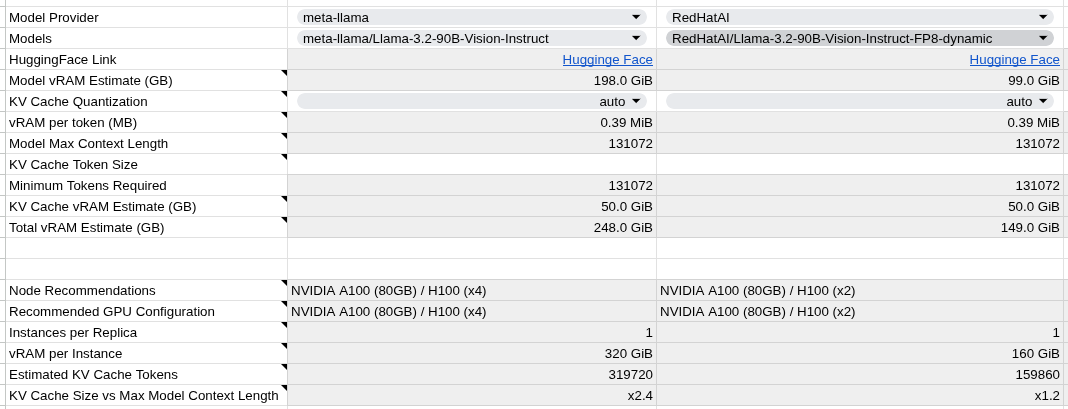
Business Impact: * 50% memory reduction (198.0 GiB → 99.0 GiB) for large multimodal model * Hardware requirement reduction from 4 GPUs to 2 GPUs * Significant cost savings on high-end GPU infrastructure * Multimodal capabilities preserved (vision + text)
Key Insights
Memory Savings by Compression Type
-
FP8 Compression: Consistent ~50% memory reduction across model sizes
-
W4A16 Quantization: Up to 70% memory reduction with evaluation requirements
-
Multimodal Support: Compression works effectively for vision-language models
Selection Guidelines
Getting Started
-
Identify your model in the Red Hat AI collection
-
Compare memory requirements using model configuration tools
-
Assess hardware compatibility with compression scheme
-
Plan evaluation approach for accuracy validation
-
Deploy compressed model with Red Hat AI support
Next Steps: Refer to the LLM Compressor Executive Guide for detailed customer engagement and deployment strategies.
Resources
-
Red Hat AI Models: huggingface.co/RedHatAI
-
Model Configuration Tools: Available through Red Hat AI platform
-
Technical Support: Contact Red Hat AI team for deployment assistance