Weights and Activation Quantization (W4A16)
In this exercise, we will use a notebook to investigate how LLMs weights and activations can be quantized to W4A16 for memory savings and inference acceleration. This quantization method is particularly useful for:
-
Reducing model size
-
Maintaining good performance during inference
The quantization process involves the following steps:
-
Load the model: Load the pre-trained LLM model
-
Choose the quantization scheme and method - Refer to the slides for a quick recap of the schemes and formats supported
-
Prepare calibration dataset: Prepare the right dataset for calibration
-
Quantize the model: Convert the model weights and activations to W4A16 format
-
Using SmoothQuant and GPTQ
-
-
Save the model: Save the quantized model to a suitable storage
-
Evaluate the model: Evaluate the quantized model’s accuracy
Pre-requisites
To start the lab, perform the following pre-requisite setup activities.
-
Create a Data Science Project
-
Create Data Connections - To store the quantized model
-
Deploy a Data Science Pipeline Server
-
Launch a Workbench
-
Clone the Git Repo
https://github.com/redhat-ai-services/etx-llm-optimization-and-inference-leveraging.gitinto the workbench
Creating a Data Science Project
-
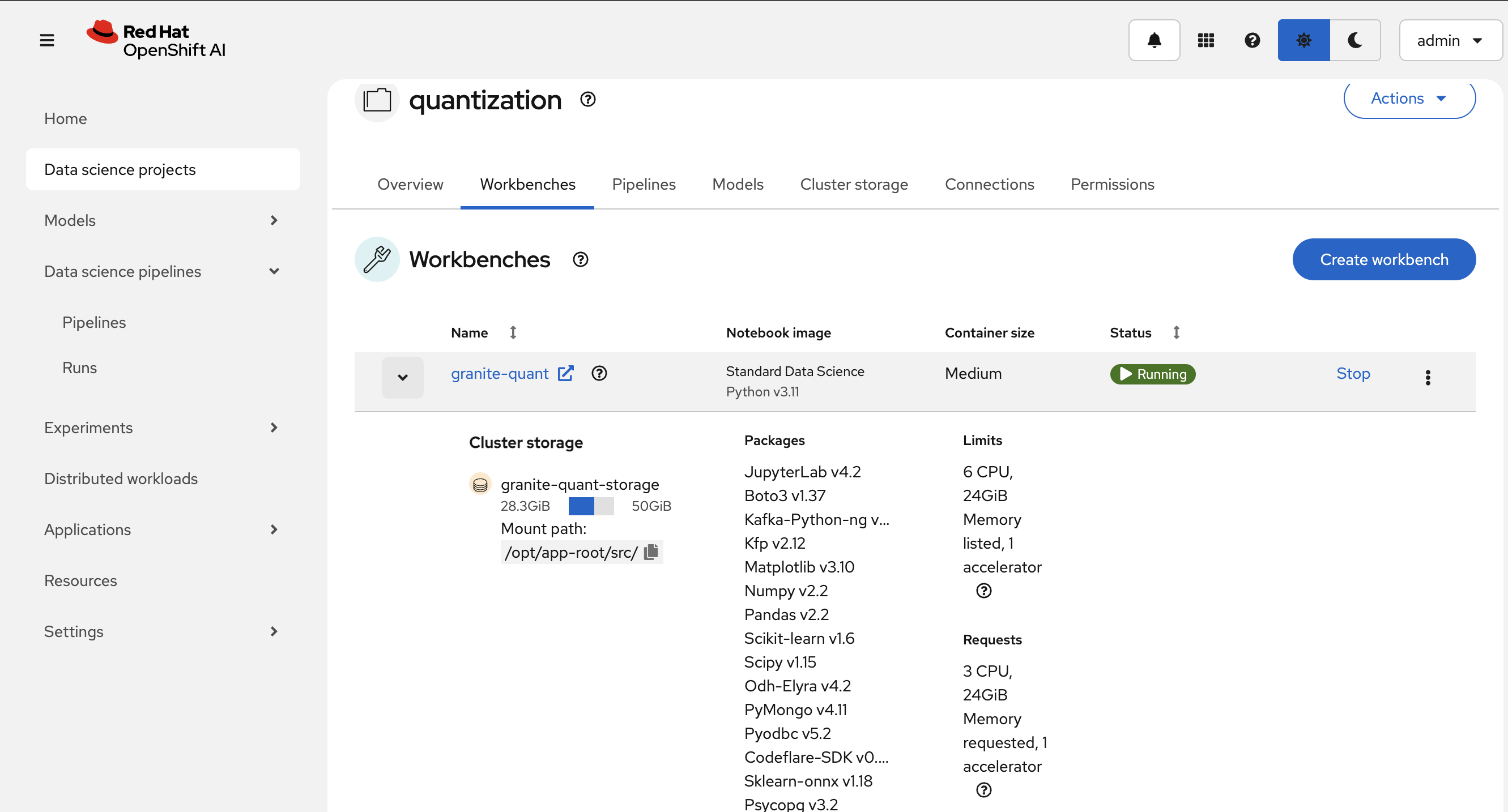
In the OpenShift AI Dashboard application, navigate to the Data Science Projects menu on the left:
 Figure 1. OpenShift AI Dashboard
Figure 1. OpenShift AI Dashboard -
Create a
Data Science projectwith the namequantization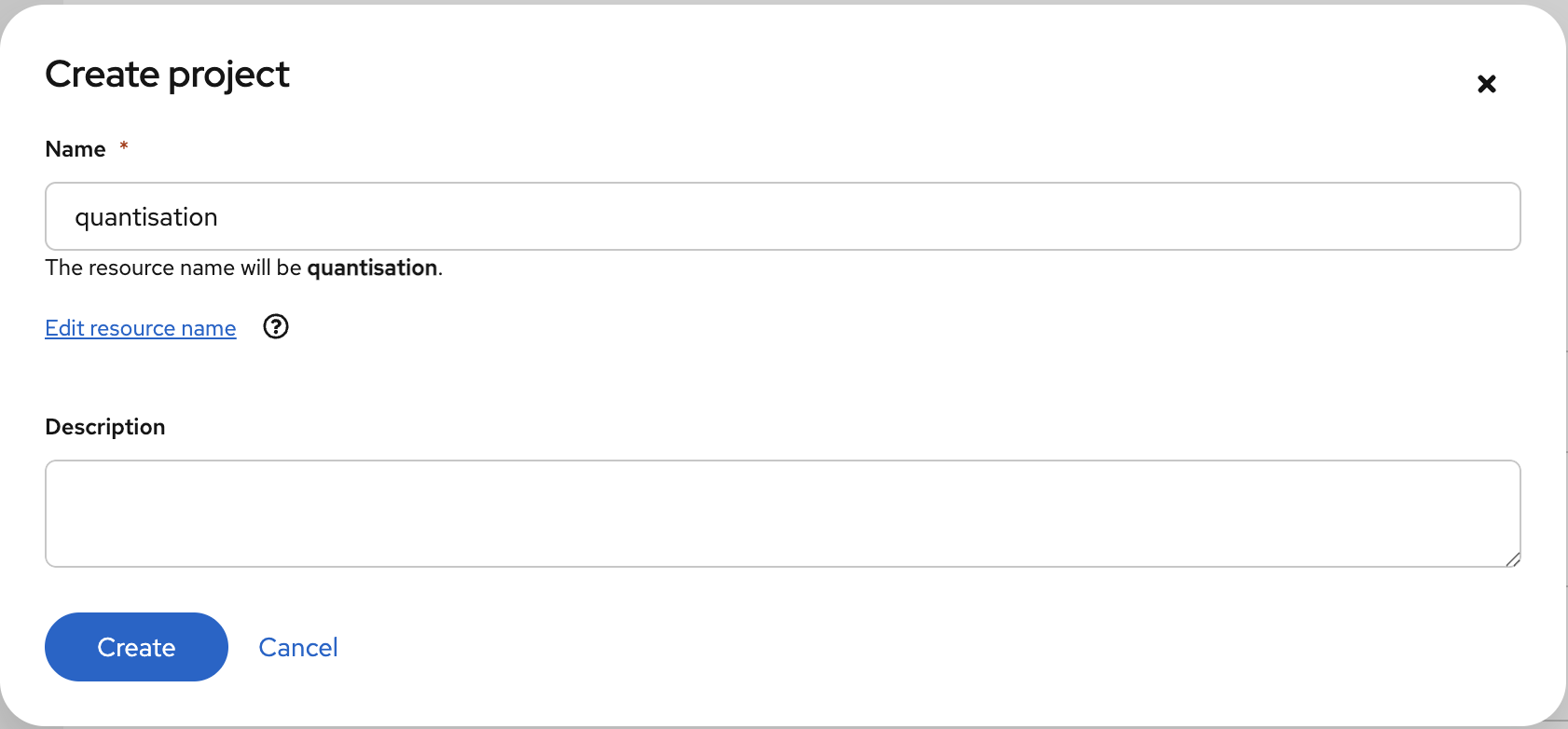 Figure 2. Project
Figure 2. Project
Creating a Data Connection for the Pipeline Server
-
To provide a S3 storage for pipeline server and for saving the quantized model to S3, create a new OpenShift Project
minioand set upMinIOby applying the manifest available atoptimization_lab/minio.yaml. The default credentials for accessing MinIO areminio/minio123
oc apply -n minio.yaml
-
Login to MinIO with the credentials
minio/minio123and create two buckets with the namespipelineandmodels. -
Create a new
Data Connectionthat points to it.
-
Select the connection type S3 compatible object storage -v1 and use the following values for configuring the MinIO connection.
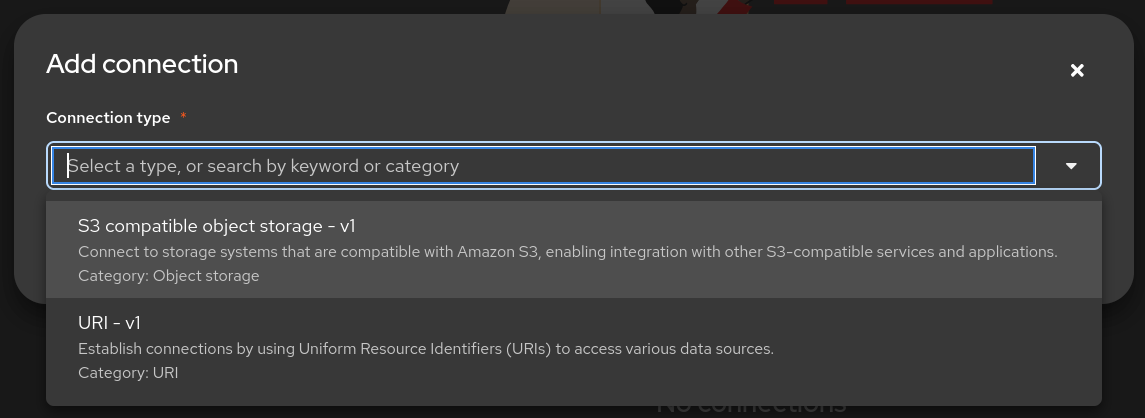 Figure 4. S3 comaptible object storage
Figure 4. S3 comaptible object storage-
Name:
Pipeline -
Access Key:
minio -
Secret Key:
minio123 -
Endpoint:
http://minio-service.minio.svc.cluster.local:9000 -
Region:
none -
Bucket:
pipelines
-
-
The result should look similar to:
 Figure 5. Result
Figure 5. Result -
Create another Data Connection with the name
minio-modelsusing the same MinIO connection details with the bucket name as "models"
Creating a Pipeline Server
-
It is recommended to create the pipeline server before creating a workbench.
-
Go to the Data Science Project
quantization→ Data science pipelines → Pipelines → click on Configure Pipeline Server Figure 6. Pipeline Server 1
Figure 6. Pipeline Server 1 -
Use the same information as in the Data Connection created earlier (Pipeline) and click the Configure Pipeline Server button:
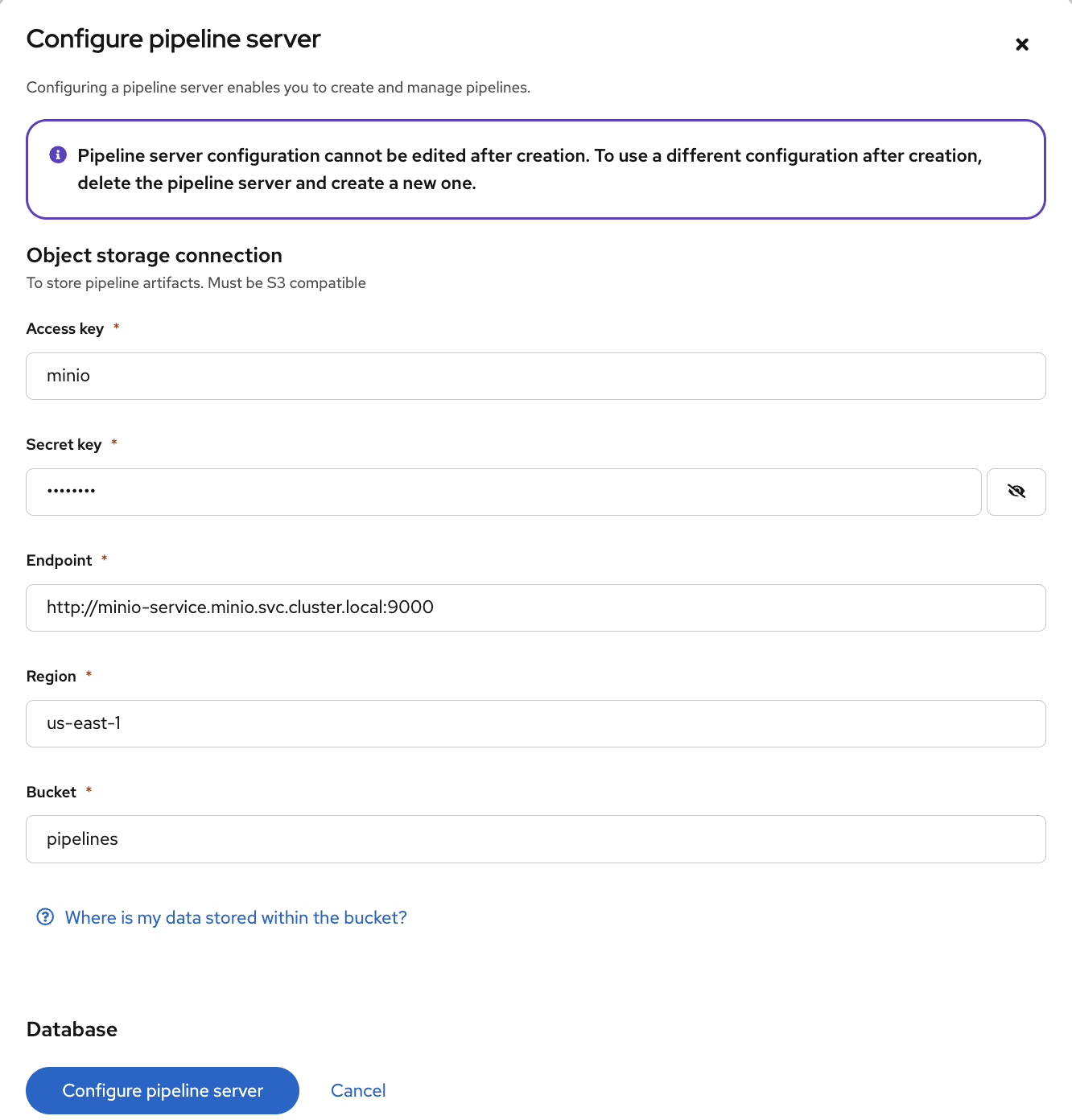 Figure 7. Pipeline Server 2
Figure 7. Pipeline Server 2 -
When the pipeline server is ready, the screen will look like the following:
 Figure 8. Pipeline Server 3
Figure 8. Pipeline Server 3
At this point, the pipeline server is ready and deployed.
| There is no need for wait for the pipeline server to be ready. You may go on to the next steps and check this out later on. This may take more than a couple of minutes to complete. |
Creating a Workbench
-
Once the Data Connection and Pipeline Server are fully created, it’s time to create the workbench
-
Go to Data Science Projects, select the project
quantization, and click on Create a workbench Figure 9. Create Workbench
Figure 9. Create Workbench -
Make sure it has the following characteristics:
-
Choose a name for it, like:
granite-quantization -
Image Selection:
Minimal PythonorStandard Data Science -
Container Size:
Medium -
Accelerator:
NVIDIA-GPU
-
-
That should look like:
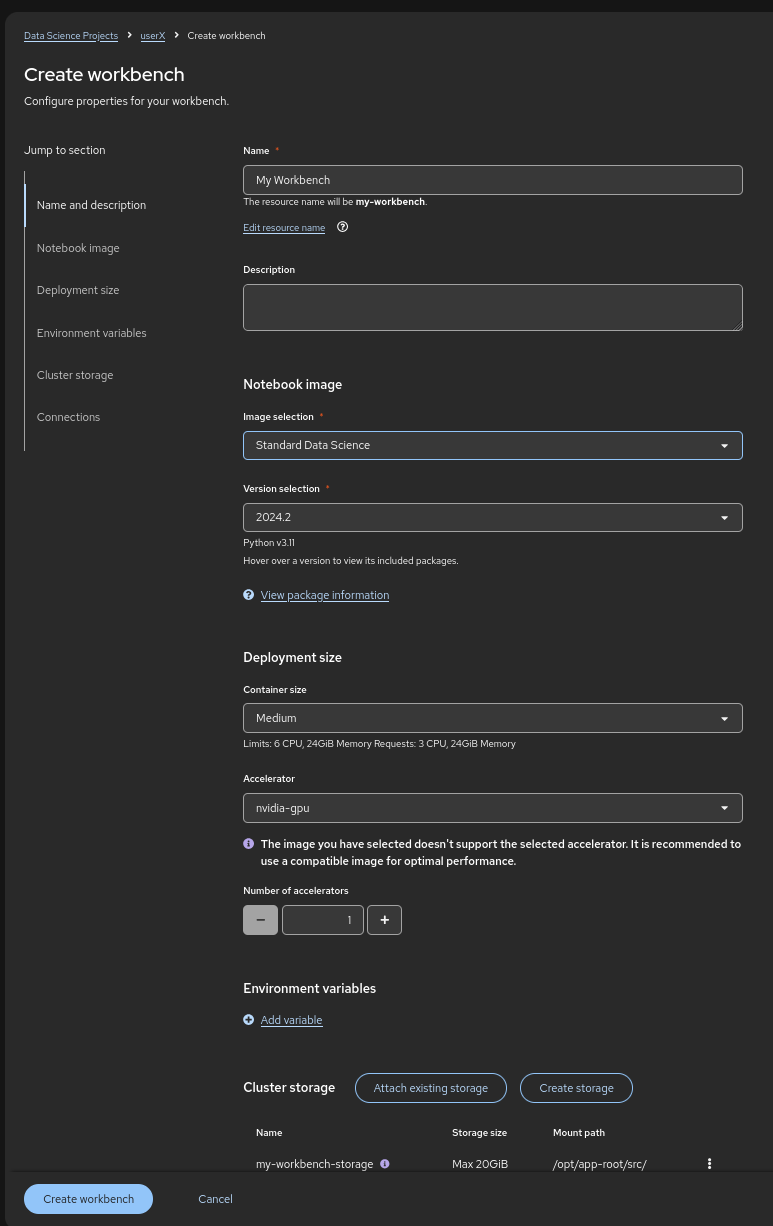 Figure 10. Launch Workbench
Figure 10. Launch Workbench -
Add the created Data Connection by clicking on the Connections section and selecting Attach existing connections. Then, click Attach for the created minio-models connection. 🔗
 Figure 11. Add Data Connection
Figure 11. Add Data Connection Figure 12. Attach Data Connection
Figure 12. Attach Data Connection -
Then, click on Create Workbench and wait for the workbench to be fully started.
-
Once it is, click the link besides the name of the workbench to connect to it!
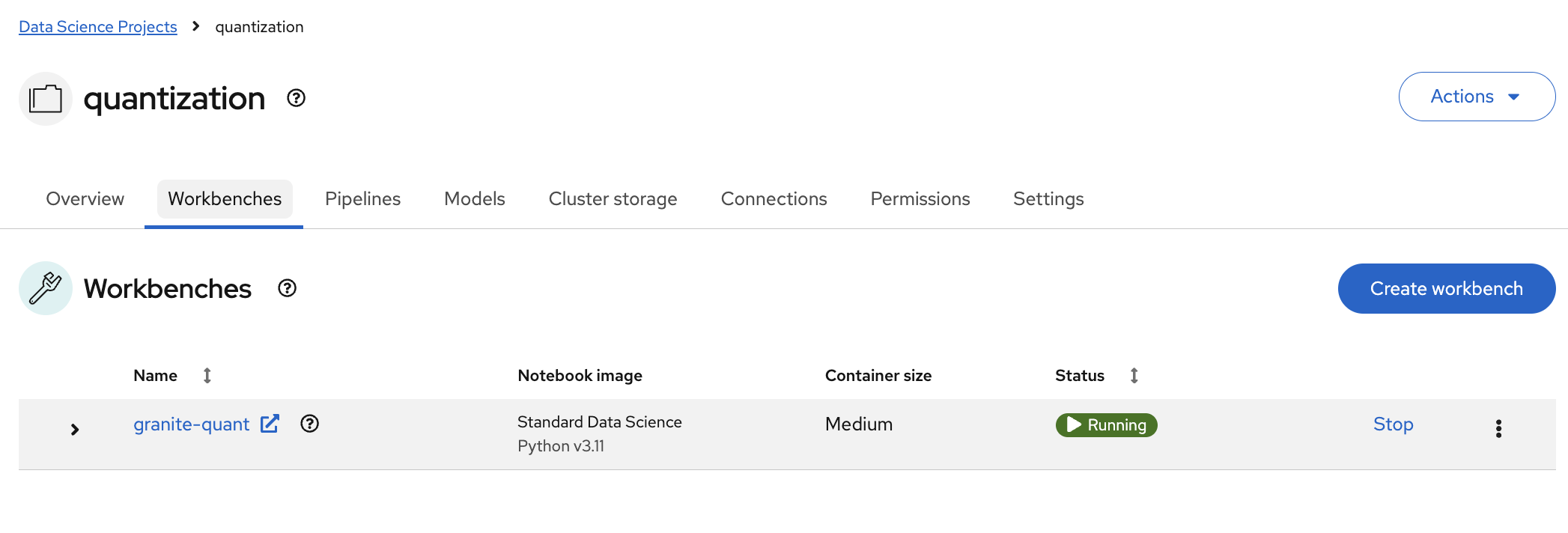 Figure 13. Open Link
Figure 13. Open Link -
Authenticate with the same credentials as earlier.
-
You will be asked to accept the following settings:
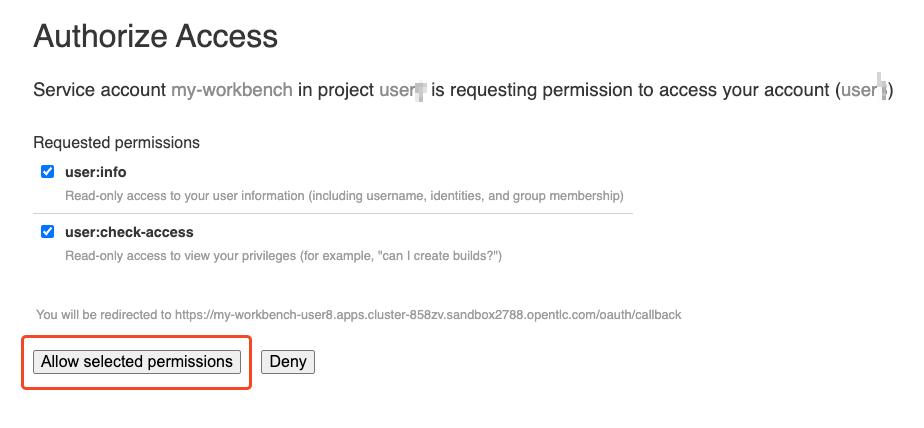 Figure 14. Accept Settings
Figure 14. Accept Settings -
Once you accept it, you should now see this:
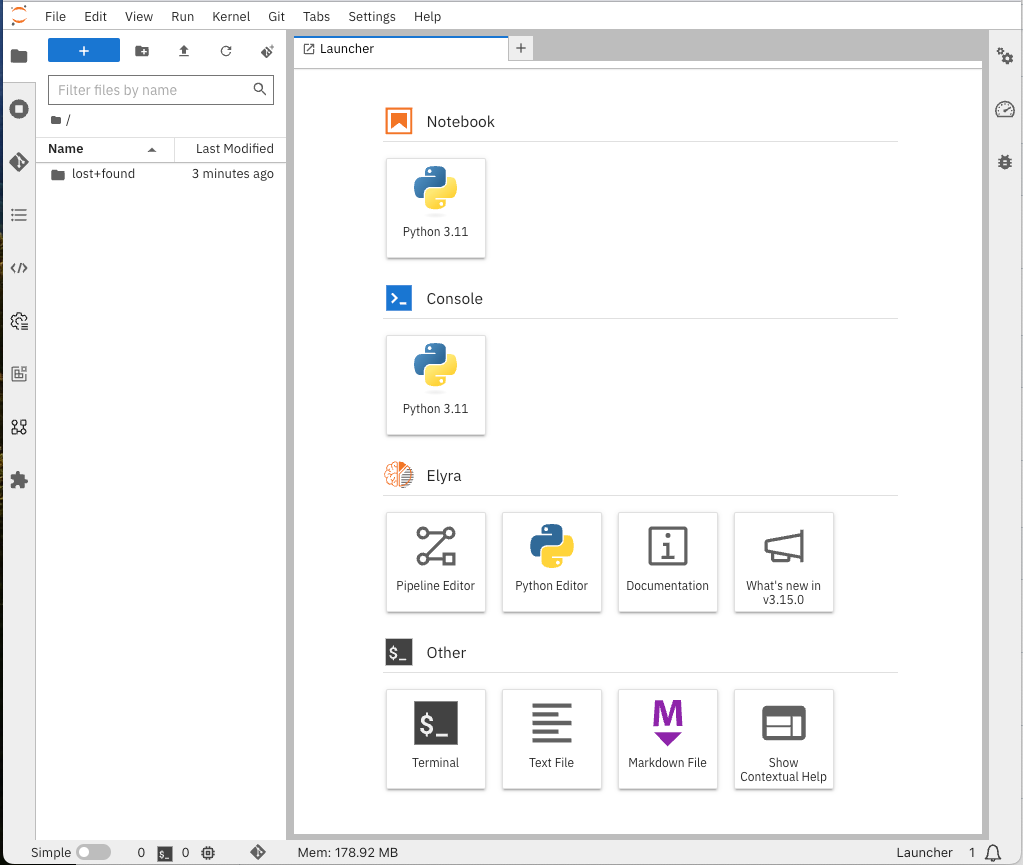 Figure 15. Jupyter
Figure 15. Jupyter
Git clone the Common Repo
We will clone the content of our Git repo so that you can access all the materials created as part of our prototyping exercise. 📚
-
Using the Git UI:
-
Open the Git UI in Jupyter:
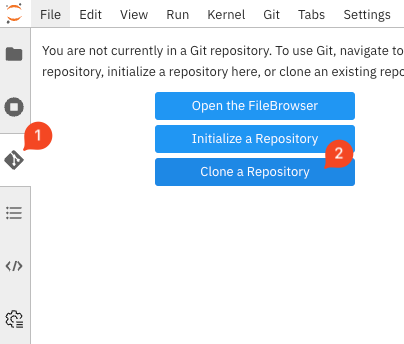 Figure 16. Git UI
Figure 16. Git UI -
Enter the URL of the Git repo:
https://github.com/redhat-ai-services/etx-llm-optimization-and-inference-leveraging.git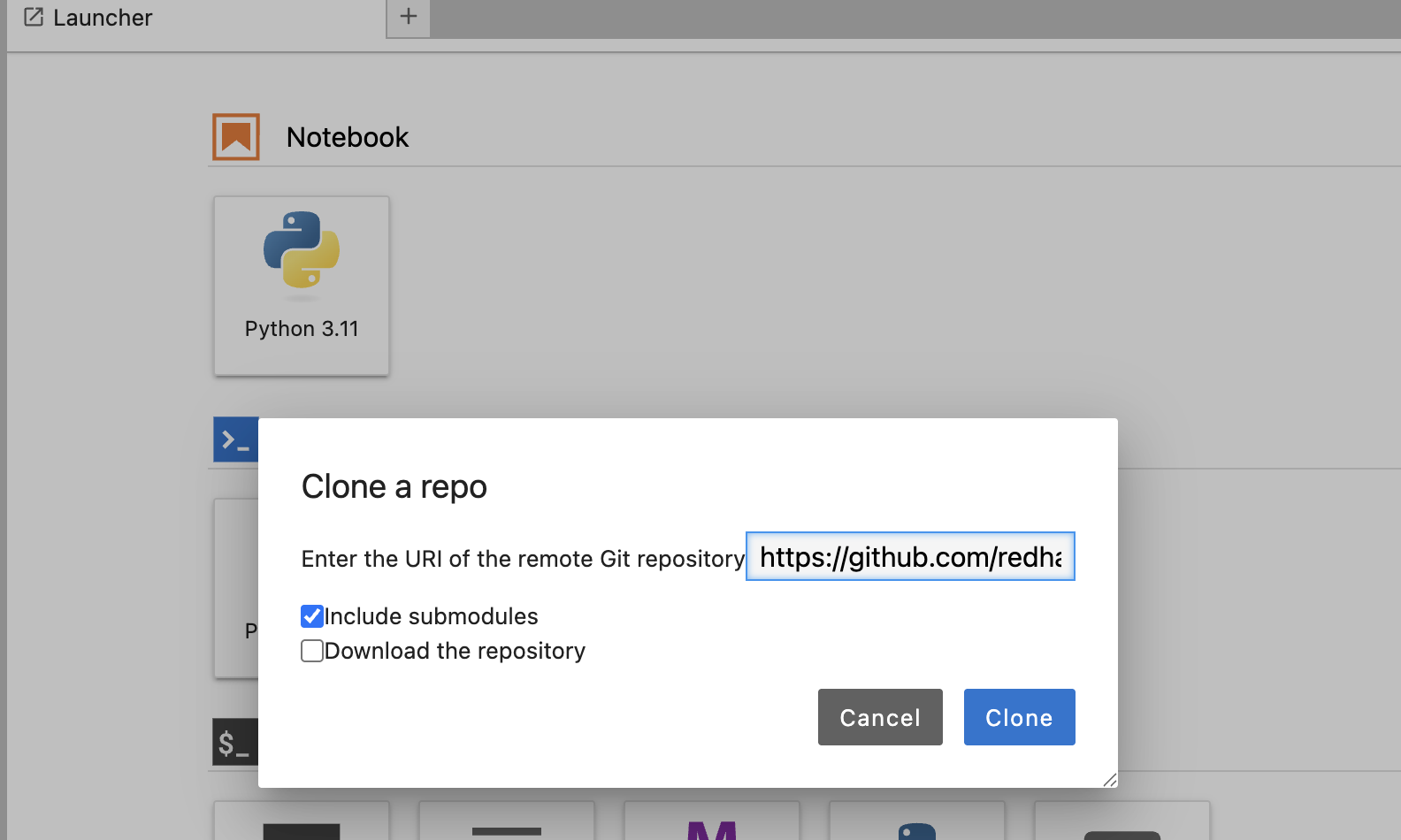 Figure 17. Git Clone
Figure 17. Git Clone
-
At this point, the project is ready for the quantization work.
Exercise: Quantize the Model with llm-compressor
From the optimization_lab/llm_compressor folder, open the notebook weight_activation_quantization.ipynb and follow the instructions.
To execute the cells you can select them and either click on the play icon or press Shift + Enter
When the cell is being executed, you can see [*]. And once the execution has completed, you will see a number instead of the *, e.g., [1]
When done, you can close the notebook and head to the next page.
| Once you complete all the quantization exercises and you no longer need the workbench, ensure you stop it so that the associated GPU gets freed and can be utilized to serve the model. |