Using Llama Stack
|
Persona: AI Engineer (primary). Also relevant: Platform Engineer. |
|
In this section
We are going to build out the LlamaStack server configuration from the ground up. Along the way we will use the LlamaStack playground UI as a test client and show how to configure providers, models and MCP servers. In the final section we will use the playground to develop our Use Case specific prompts. |
|
Estimated time: 60–90 minutes |
What you’ll do
-
Deploy Llama Stack and Playground
-
Register builtin/MCP tools
-
Develop and refine prompts in Playground
-
Capture configuration and decisions for later modules
Create an LLM
It is nice to have a small LLM available locally to validate the default deployment of LlamaStack. We can test in an isolated fashion our configuration.
Since we have a GPU available we can deploy the models gitops application which contains a reference deployment of the granite-31-2b-instruct model. The same app also deploys out the secrets for the Models as a Service (MaaS) that we setup in the bootstrap phase.
-
Rename the file infra/app-of-apps/sno/models.yaml.undeploy → infra/app-of-apps/sno/models.yaml
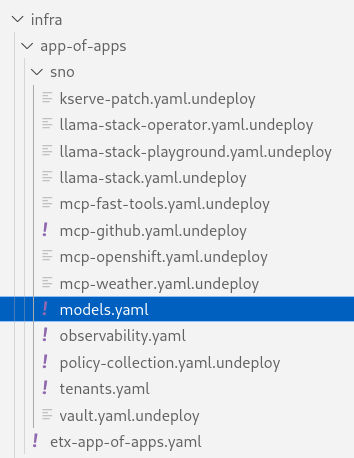
-
Check this file into git
# Its not real unless its in git git add .; git commit -m "deploy default models"; git push -
Check Argo CD that models has appeared under the etx-app-of-apps
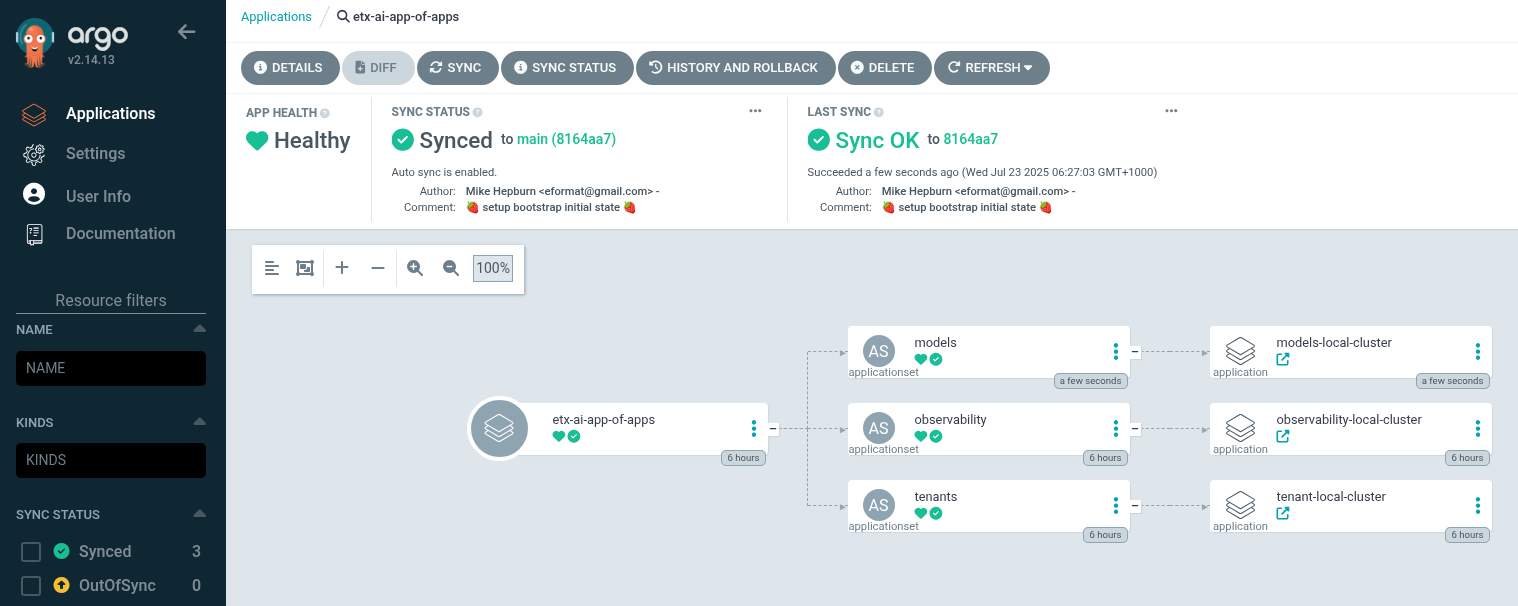
-
Navigate to ACM by clicking the dropdown in the top left of the OpenShift console to select
All Clusters
-
Then select
Governancefrom the left hand menu
-
Then select
Policiesfrom the left hand menu
-
Check ACM Policies that models-serving has appeared with the expected results.
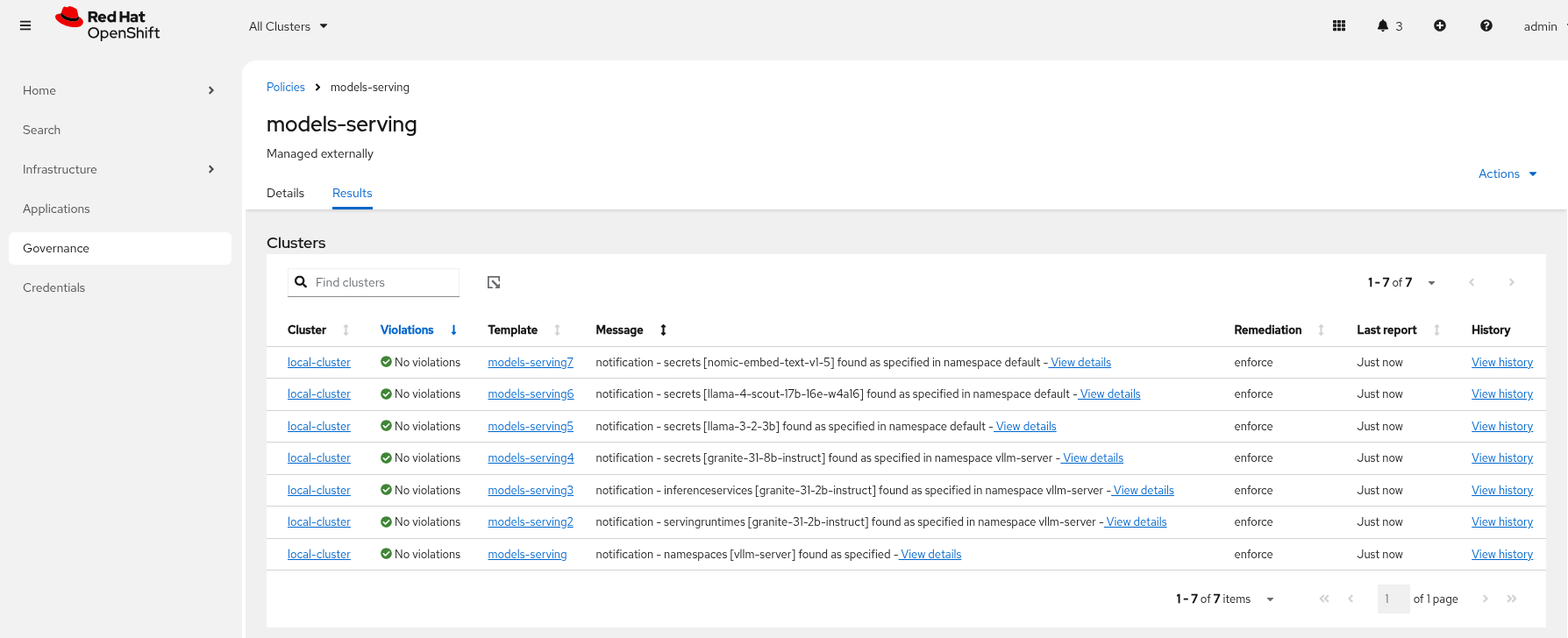
-
Check in RHOAI that there is a model deployment in the vllm-server namespace
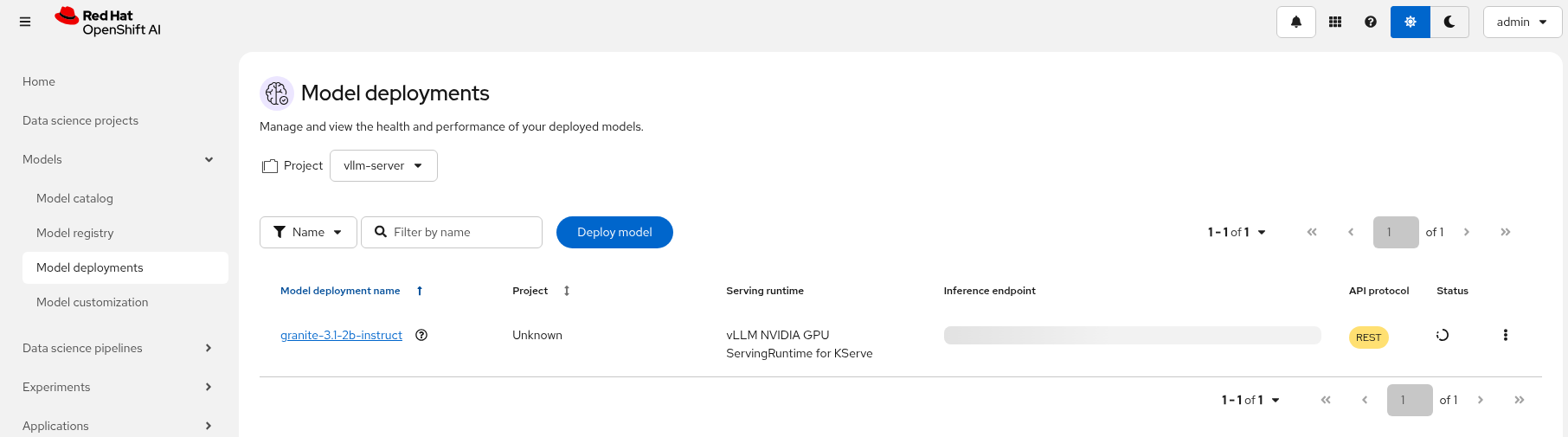
Check the pod status oc get pods -n vllm-server -
Check that the external route becomes available in RHOAI.
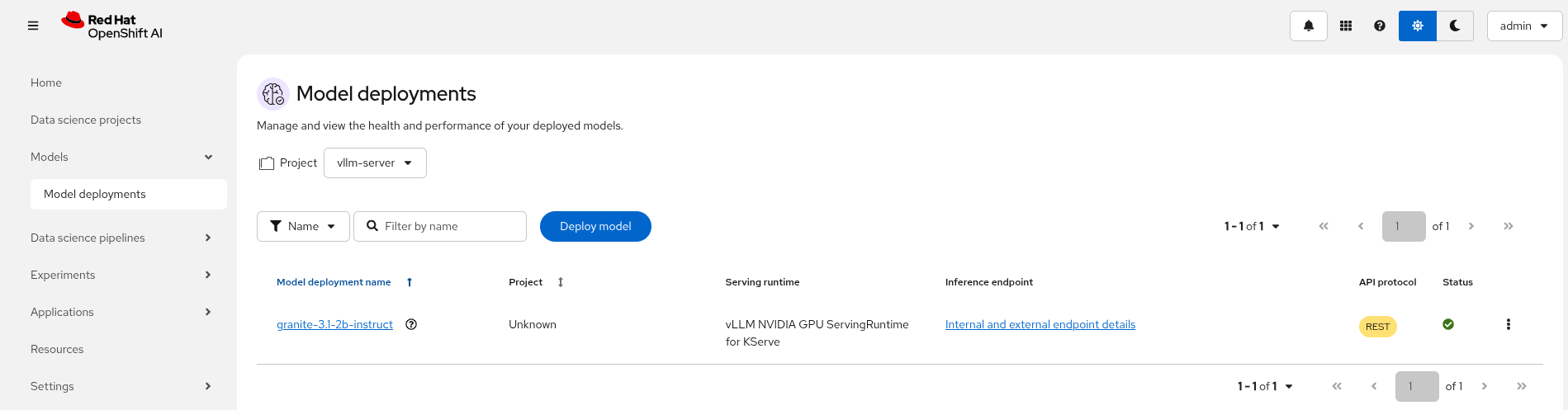
-
Next, check that the model’s OpenAI docs can be seen in OpenAPI. Copy the external endpoint as shown
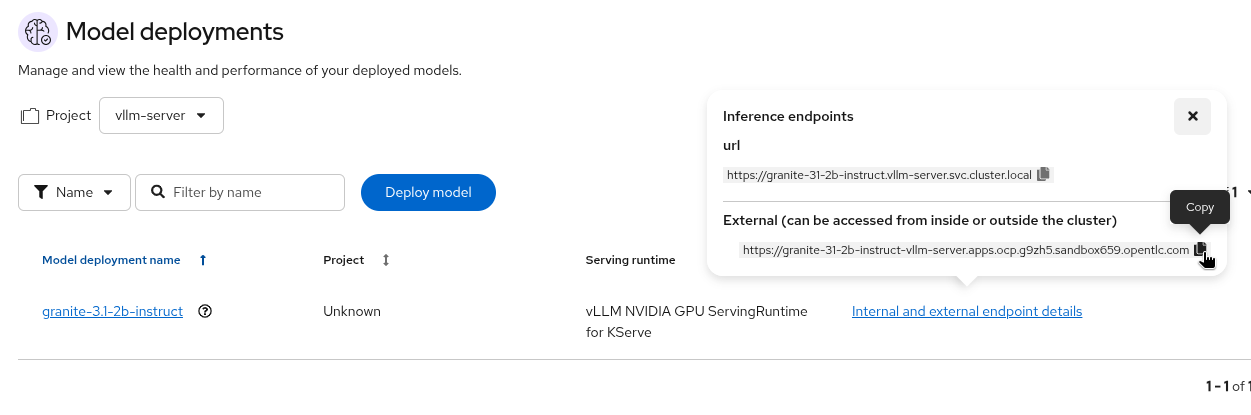
-
Paste the external endpoint into your browser and append /docs to the URL to browse them
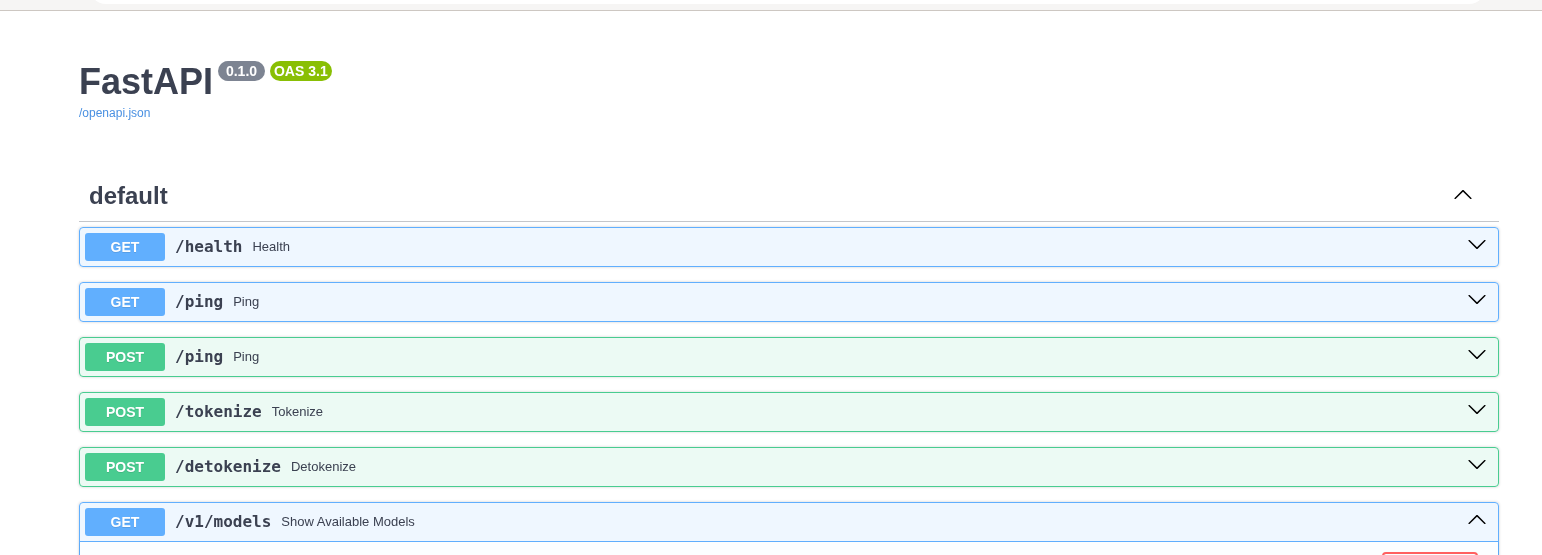
-
Check the call to the models endpoint /v1/models returns OK by selecting "Try it out" and then "Execute"
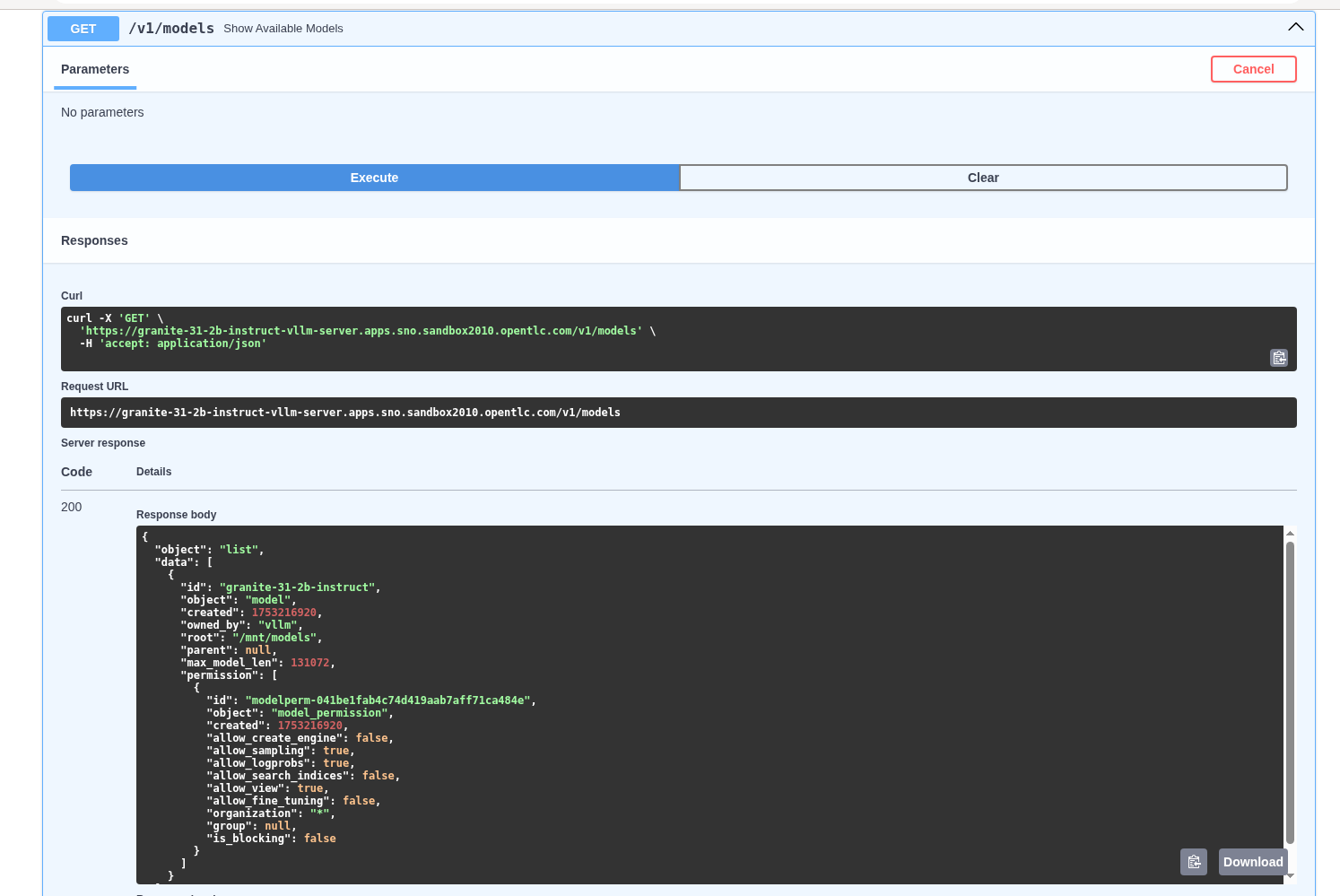
-
To learn more about the model deployment, you can checkout the code here infra/applications/models/base/granite/granite-31-2b-vllm-oci.yaml
LlamaStack
LlamaStack is the open-source framework for building generative AI applications. We are going to deploy LlamaStack using the Operator and then take a look around using the client CLI and the playground UI.
LlamaStack K8s Operator
The Llama Stack K8s Operator is a Kubernetes operator that automates the deployment and management of Llama Stack servers in Kubernetes environments. It provides a declarative way to manage AI model serving infrastructure. It is:
-
Kubernetes native and follows standard operator development pattern.
-
Supports Ollama and vLLM inference providers
-
Allows configuring and managing LlamaStack servers and client instances.
DataScienceCluster Custom Resource
-
Rename the file infra/app-of-apps/sno/llama-stack-operator.yaml.undeploy → infra/app-of-apps/sno/llama-stack-operator.yaml
-
Check this file into git
# Its not real unless its in git git add .; git commit -m "deploy llamastack operator"; git push -
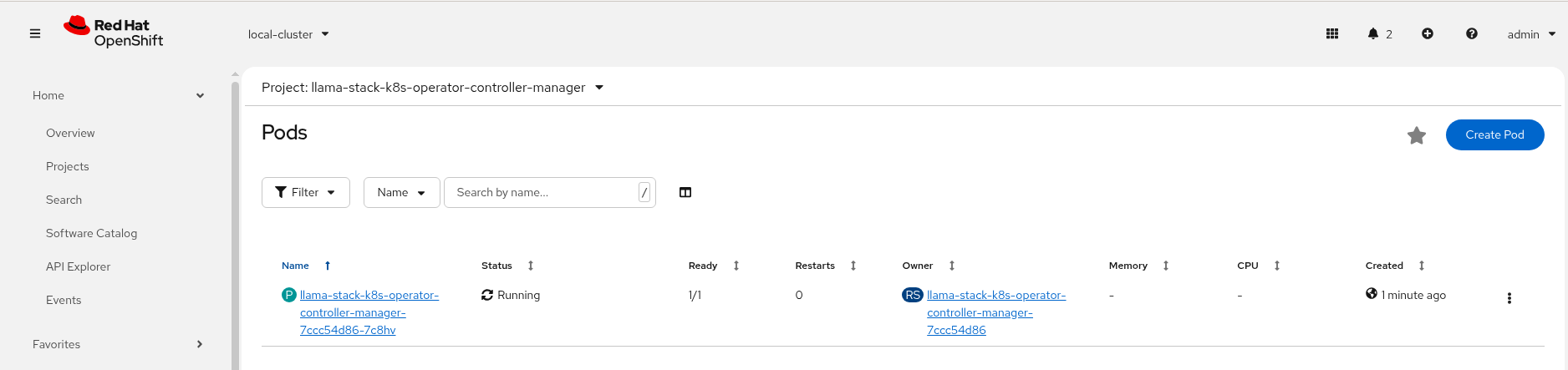
Check the LlamaStack controller manager pod is running in the llama-stack-k8s-operator-controller-manager Namespace
LlamaStackDistribution Custom Resource
The LlamaStackDistribution is the main custom resource that defines how a Llama Stack server should be deployed. It allows you to specify:
-
Server Configuration: Which distribution to use (Ollama, vLLM, etc.)
-
Container Specifications: Port, environment variables, resource limits
You may have many LlamaStackDistribution instances deployed in a cluster.
Example LlamaStackDistribution
Here is a very basic configuration. Note that the RHOAI distribution is named rh-dev and the upstream is named remote-vllm
apiVersion: llamastack.io/v1alpha1
kind: LlamaStackDistribution
metadata:
name: llamastack-with-config
spec:
replicas: 1
server:
distribution:
name: rh-dev # remote-vllm (upstream)
containerSpec:
port: 8321
userConfig:
# reference to the configmap that contains Llama stack configuration.
configMapName: llama-stack-config| We maintain a build of LlamaStack that pins the image version so we can ensure stability whilst the upstream rapidly changes. We expect to use the rh-dev distribution once Using the DataScienceCluster Resource to configure the LlamaStack Operator is resolved. |
Using ConfigMap for run.yaml Configuration
The operator supports using ConfigMaps to store the run.yaml configuration file.
-
Centralized Configuration: Store all Llama Stack settings in one place
-
Dynamic Updates: Changes to the ConfigMap automatically restart pods to load new configuration
-
Environment-Specific Configs: Use different ConfigMaps for different environments
ConfigMap Basic Example
-
Here is a basic example of the run.yaml config provided to our LlamaStack deployment that has just the Tavily Web Search provider configured.
apiVersion: v1 kind: ConfigMap metadata: name: llamastack-config data: run.yaml: | # Llama Stack configuration version: '2' image_name: vllm apis: - tool_runtime providers: tool_runtime: - provider_id: tavily-search provider_type: remote::tavily-search config: api_key: ${env.TAVILY_API_KEY} max_results: 3 tools: - name: builtin::websearch enabled: true tool_groups: - provider_id: tavily-search toolgroup_id: builtin::websearch server: port: 8321 -
Rename the file infra/app-of-apps/sno/llama-stack.yaml.undeploy → llama-stack.yaml
-
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the basic/ folder
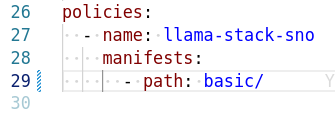
If PolicyGenerator is new to you, checkout the policy generator product documentation -
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack distribution"; git push -
Check Argo CD, ACM for LlamaStack
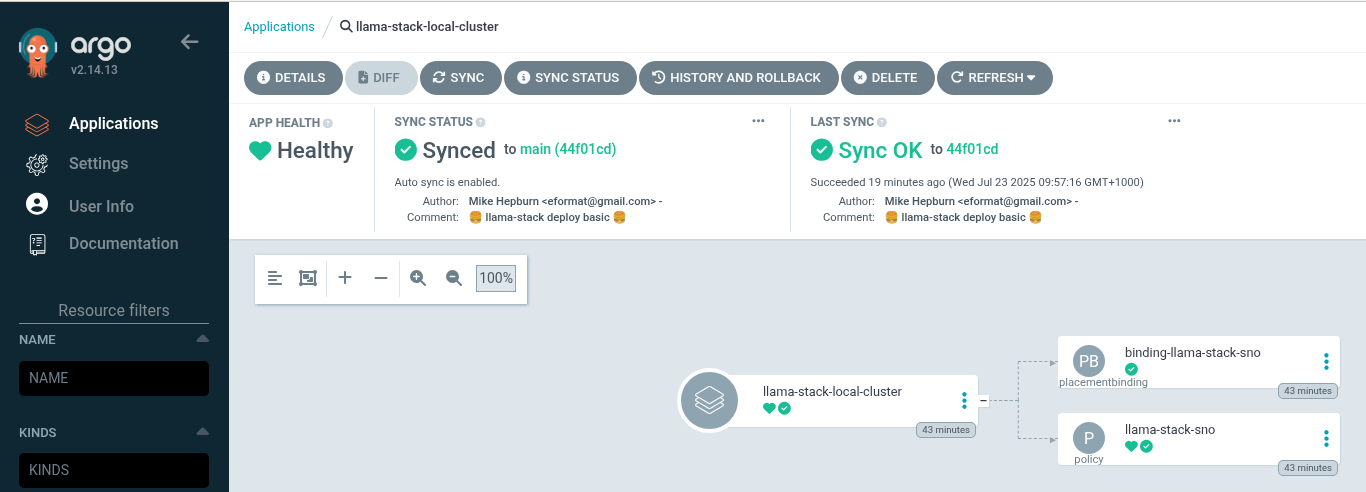
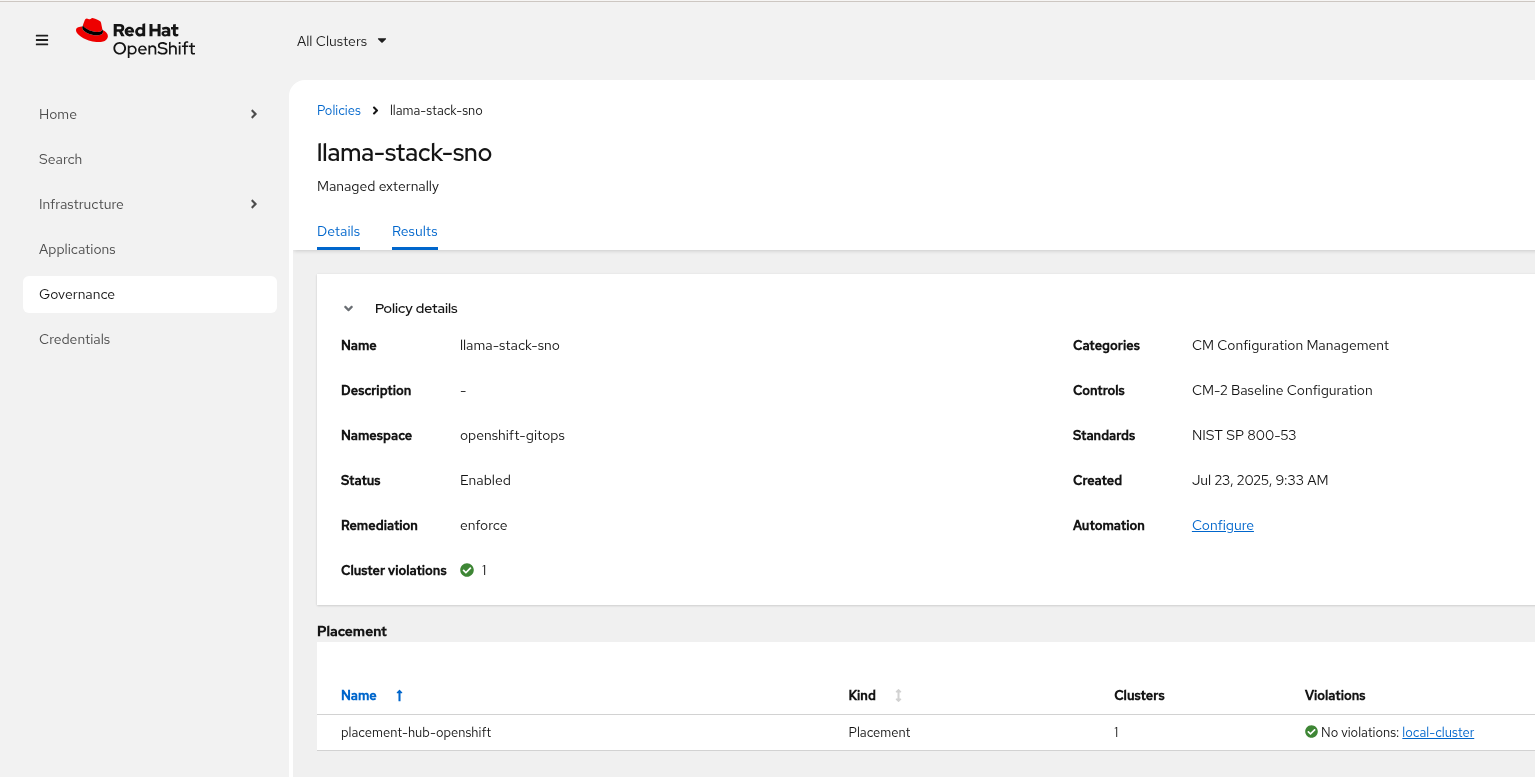
-
Check LlamaStack pod is running OK, check its logs
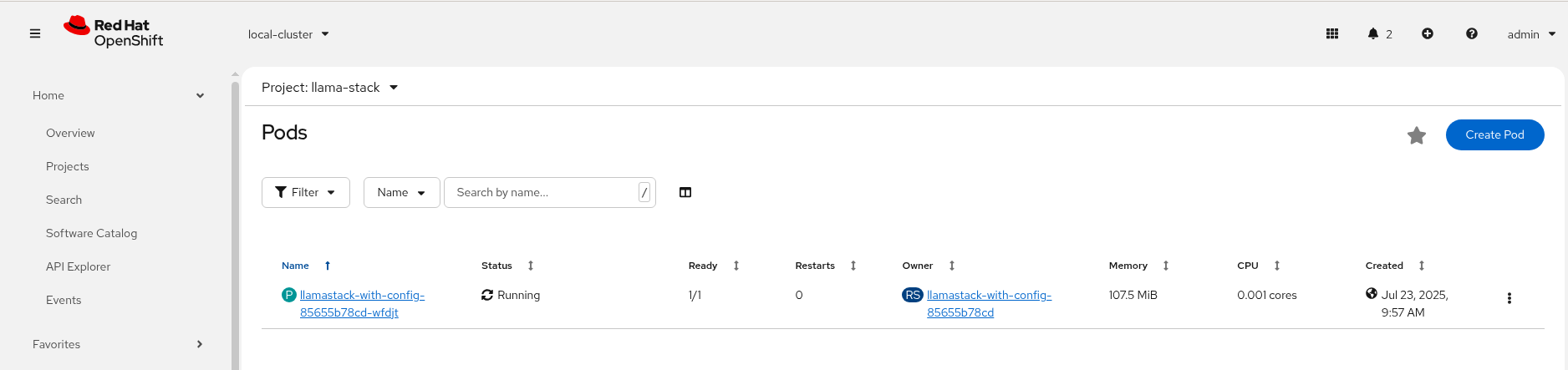
-
Install the llama-stack-client - either in a notebook, or from your jumphost - ideally we match client and server versions
pip install llama-stack-client==0.2.15If you are doing this with an older version of python (3.11 or less) you may not be able to install the matching version. Run using this instead pip install llama-stack-client fire -
Login to OpenShift if you are not already logged in
oc login --server=https://api.${CLUSTER_NAME}.${BASE_DOMAIN}:6443 -u admin -p ${ADMIN_PASSWORD} -
Port forward the LlamaStack port so we can connect to it (in a workbench you can use the Service as the --endpoint argument or just oc login and then port-forward)
oc -n llama-stack port-forward svc/llamastack-with-config-service 8321:8321 2>&1>/dev/null &You will need to restart this port-forward every time the LlamaStack pod restarts.
Each new change to the LlamaStack ConfigMap (overlay path in the policy generator) causes the LlamaStack pod to restart. So keep the port-forward command handy in your history as you will need it!.
-
Check the connection by listing the version - ideally we match client and server versions
llama-stack-client inspect versionINFO:httpx:HTTP Request: GET http://localhost:8321/v1/version "HTTP/1.1 200 OK" VersionInfo(version='0.2.15') -
If you need help with the client commands, take a look at
llama-stack-client --help -
Now list the providers - this should match what we have configured so far i.e. Tavily Web Search
llama-stack-client providers listINFO:httpx:HTTP Request: GET http://localhost:8321/v1/providers "HTTP/1.1 200 OK" ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ API ┃ Provider ID ┃ Provider Type ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━┩ │ tool_runtime │ tavily-search │ remote::tavily-search │ └──────────────┴───────────────┴───────────────────────┘ -
Check the LlamaStack OpenAPI docs at http://localhost:8321/docs
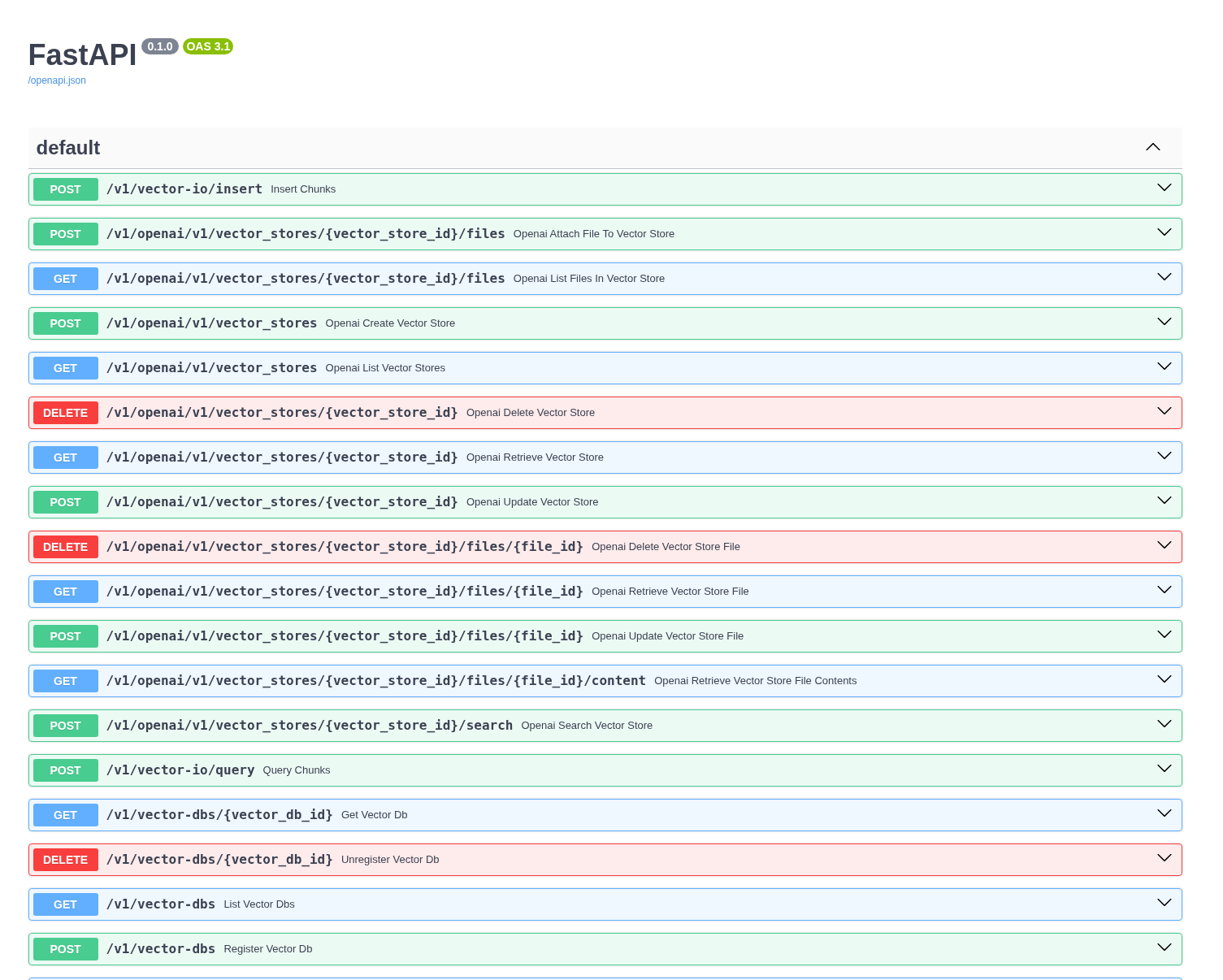
Browsing will not work in a workbench -
Done ✅
ConfigMap Basic Model Example
-
Lets add our granite-31-2b model to LlamaStack. As it is being served up by vLLM, we add a remote::vllm provider to LlamaStack under providers/inference in the run.yaml. We can set various config parameters such as the model name, the context length, tls verification and the model OpenAI endpoint URL with /v1 appended to it. We also set up a models entry as well as adding the -inference to apis.
apiVersion: v1 kind: ConfigMap metadata: name: llamastack-config data: run.yaml: | # Llama Stack configuration version: '2' image_name: vllm apis: - inference - tool_runtime models: - metadata: {} model_id: granite-31-2b-instruct provider_id: vllm provider_model_id: granite-31-2b-instruct model_type: llm providers: inference: - provider_id: vllm provider_type: "remote::vllm" config: url: "https://granite-31-2b-instruct.vllm-server.svc.cluster.local/v1" name: llama3.2:1b context_length: 4096 tls_verify: false tool_runtime: - provider_id: tavily-search provider_type: remote::tavily-search config: api_key: ${env.TAVILY_API_KEY} max_results: 3 tools: - name: builtin::websearch enabled: true tool_groups: - provider_id: tavily-search toolgroup_id: builtin::websearch server: port: 8321 -
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the basic-model/ folder
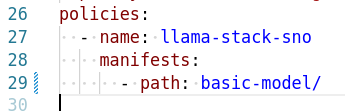
-
Check this file into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with basic-model"; git push -
When we update the ConfigMap run.yaml the LlamaStack Pod is restarted automatically by the controller
-
Now list the providers again - this should match what we have configured so far i.e. Tavily Web Search and Inference
llama-stack-client providers listINFO:httpx:HTTP Request: GET http://localhost:8321/v1/providers "HTTP/1.1 200 OK" ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ API ┃ Provider ID ┃ Provider Type ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━┩ │ inference │ vllm │ remote::vllm │ │ tool_runtime │ tavily-search │ remote::tavily-search │ └──────────────┴───────────────┴───────────────────────┘ -
Now list the models
llama-stack-client models listINFO:httpx:HTTP Request: GET http://localhost:8321/v1/models "HTTP/1.1 200 OK" Available Models ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ model_type ┃ identifier ┃ provider_resource_id ┃ metadata ┃ provider_id ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ llm │ granite-31-2b-instruct │ granite-31-2b-instruct │ │ vllm │ └──────────────────────────────┴──────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────┴────────────────────────┴───────────────────────────────┘ Total models: 1
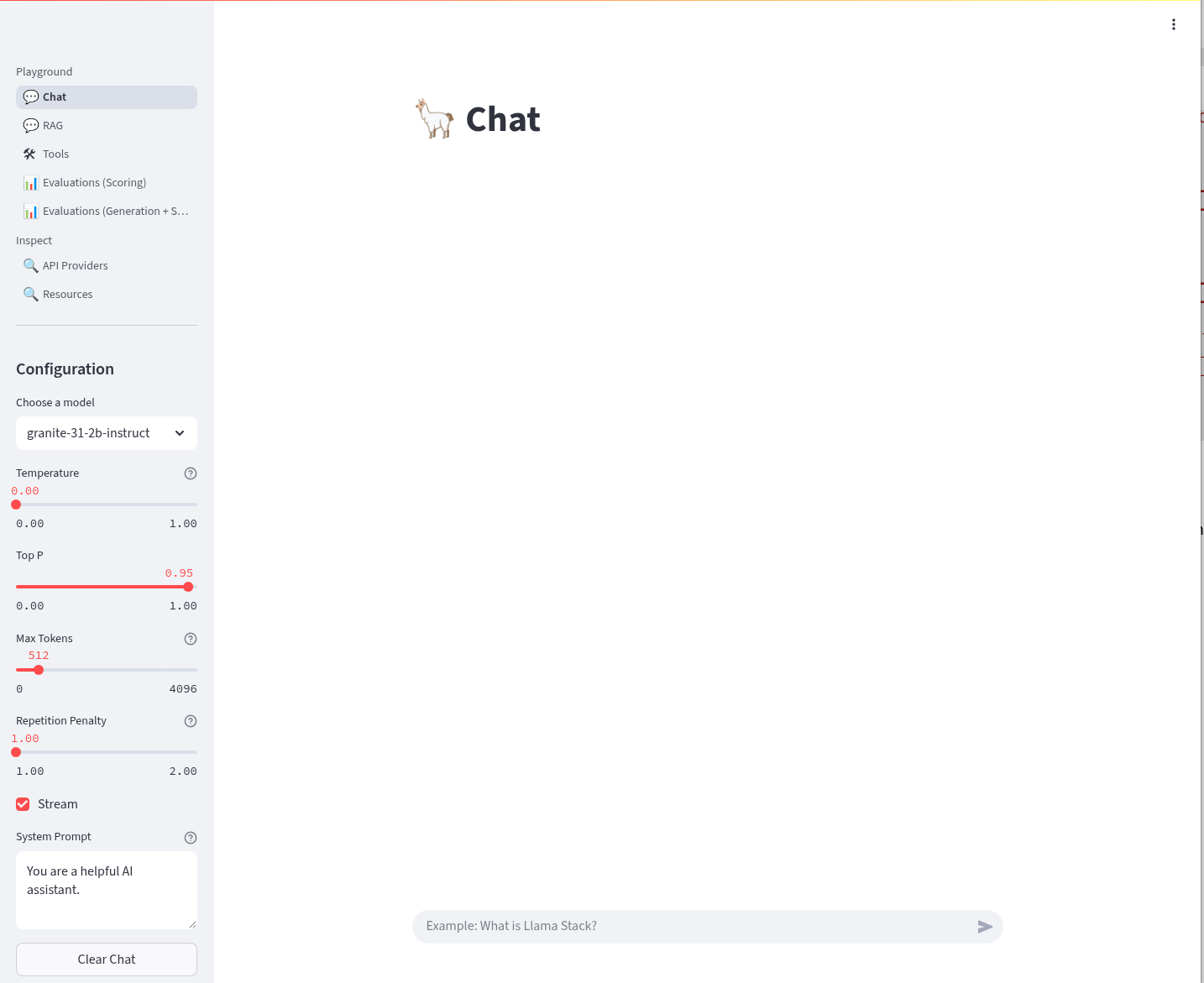
LlamaStack User Interface
-
LlamaStack comes with a simple UI. Let’s deploy it so we can start using our LLM and Web Search tool. Rename the file infra/app-of-apps/sno/llama-stack-playground.yaml.undeploy → llama-stack-playground.yaml

-
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack-playground"; git push -
Check Argo CD, ACM and the llama-stack-playground Deployment in the llama-stack Namespace
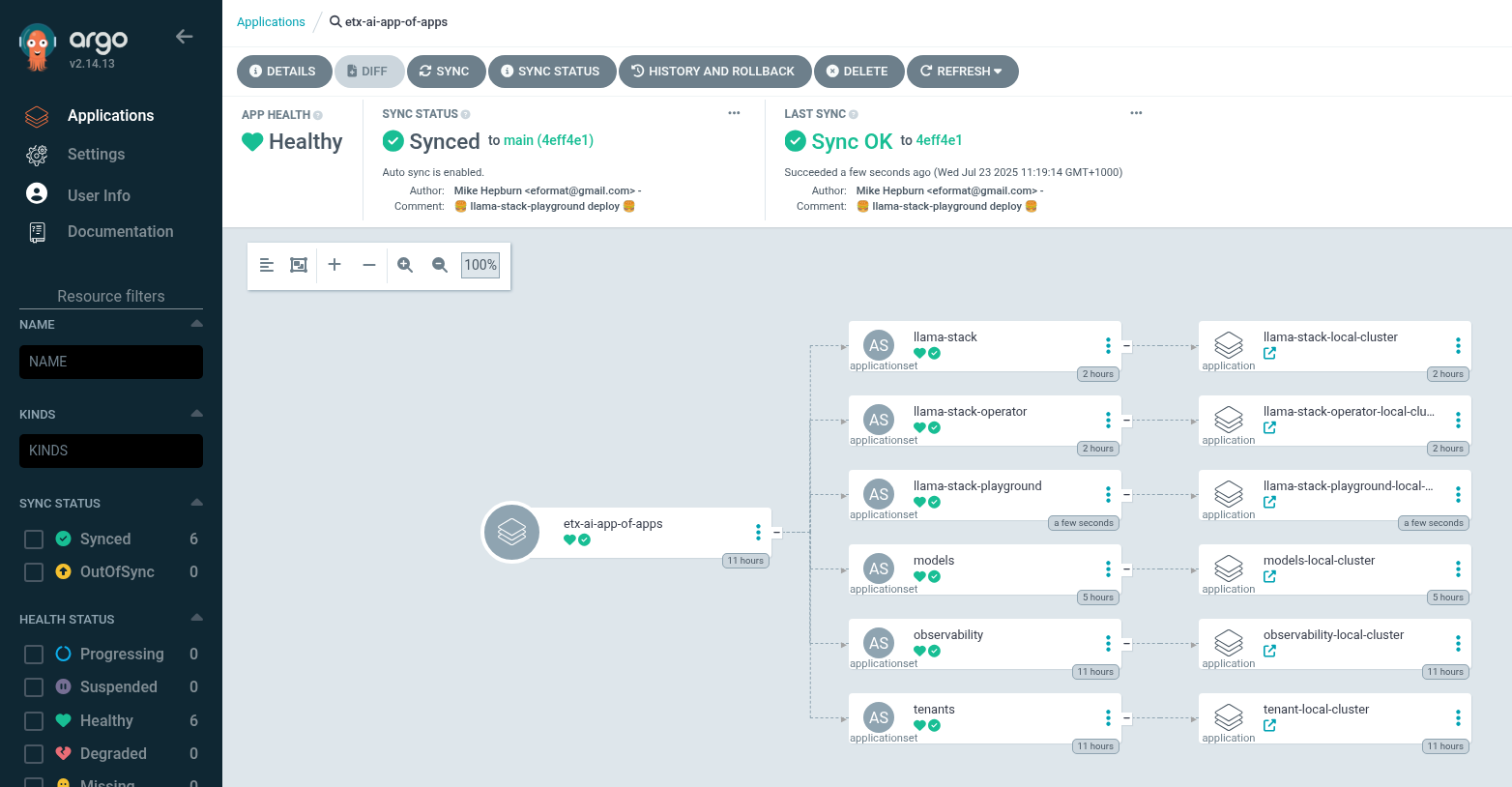
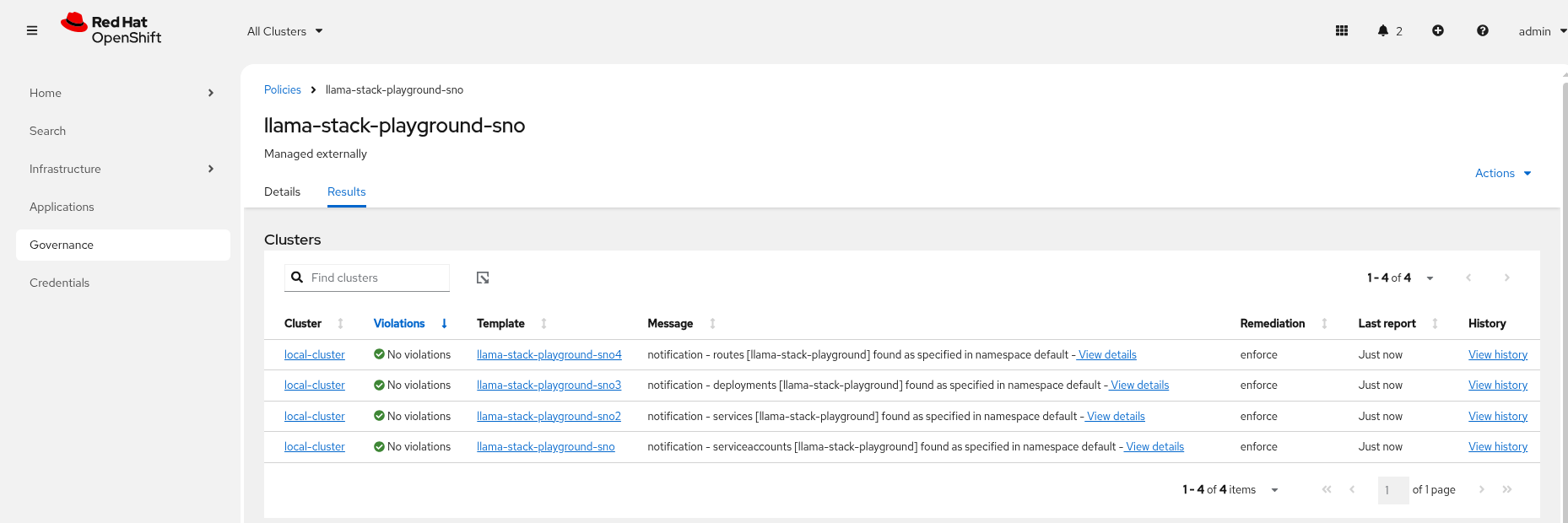
-
We can Chat with the LLM - this calls the /v1/chat/completion endpoint that we can find in the OpenAI docs for the vLLM served model. You can prompt it to check the connection is working. Ask the LLM a more complex question such as:
What is LlamaStack ?to see if it contains that information.
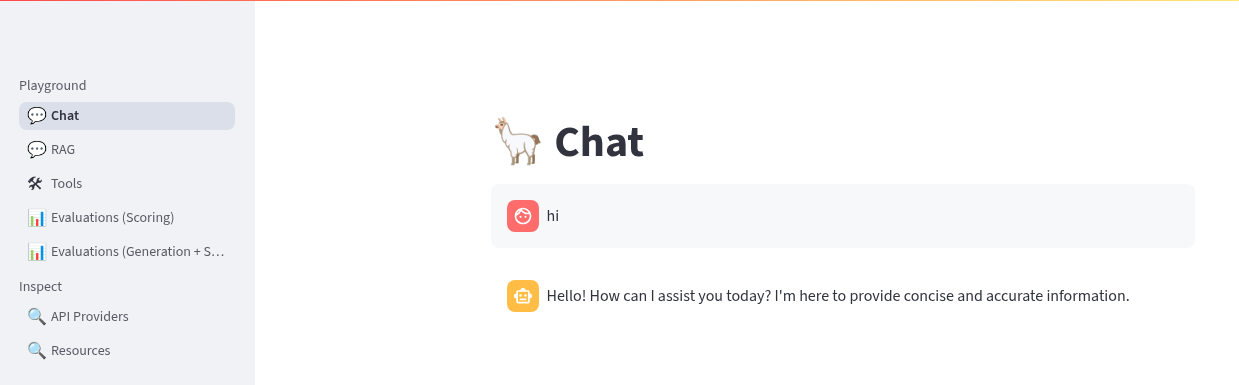
-
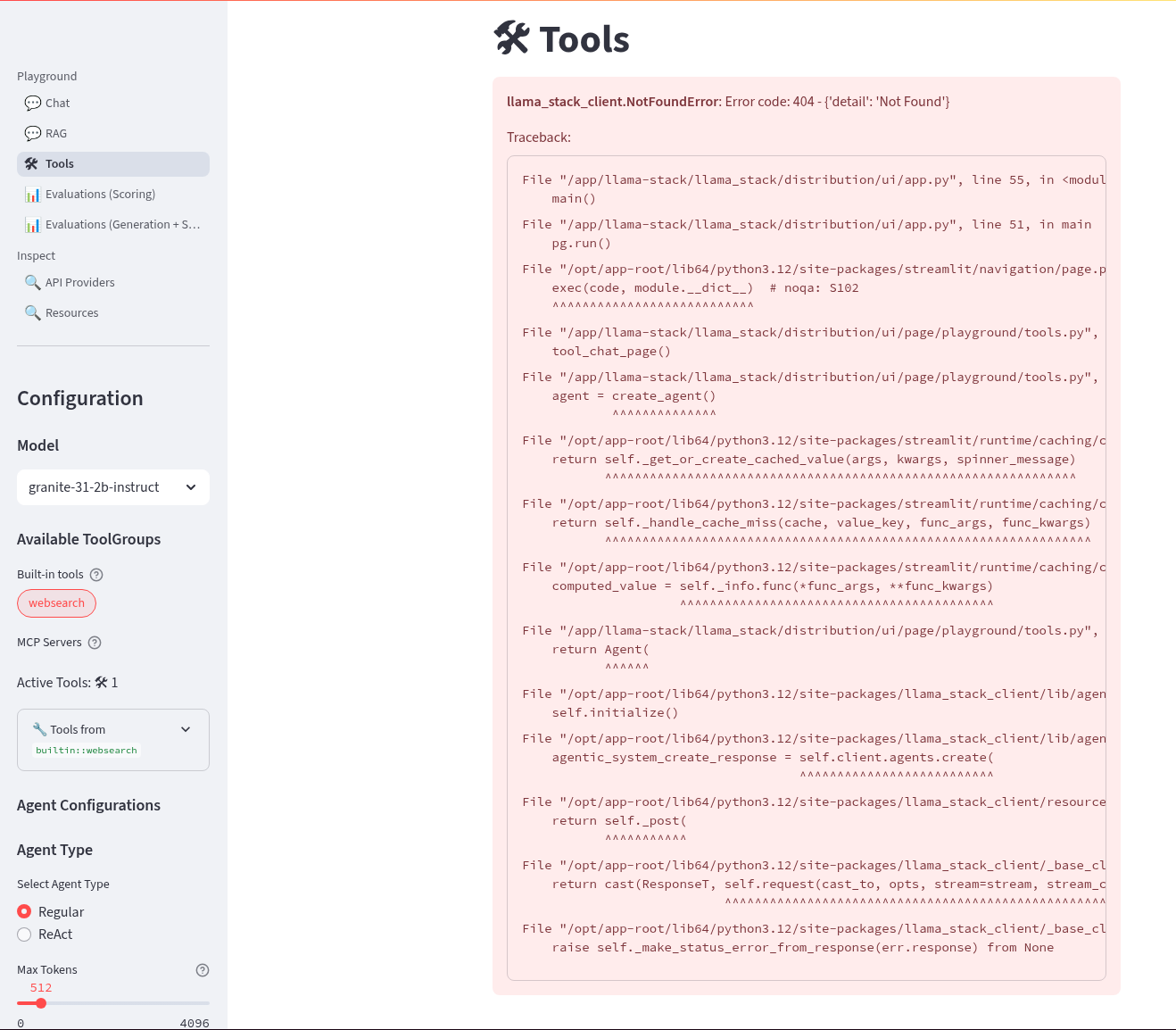
If we select the Tools section in the playground we should get an error that looks like this. It is instructive to debug this a little. We can see the built in tools websearch is configured OK on the left of the UI. If we read the stack trace error we see that the code seems to be erroring on Agent. So, we will need to configure a basic agent config for the Tool’s section of the playground to work.
-
We have added in the agents configuration under the basic-model-agent overlay. It includes the following additions.
kind: ConfigMap apiVersion: v1 metadata: name: llama-stack-config namespace: llama-stack data: run.yaml: | apis: - agents - safety - vector_io ... providers: agents: - provider_id: meta-reference provider_type: inline::meta-reference config: persistence_store: type: sqlite db_path: ${env.SQLITE_STORE_DIR:=~/.llama/distributions/starter}/agents_store.db responses_store: type: sqlite db_path: ${env.SQLITE_STORE_DIR:=~/.llama/distributions/starter}/responses_store.db ... -
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the basic-model/ folder

-
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with basic-model-agent"; git push -
Once LlamaStack pod restarts, we can Refresh the playground UI and the error should now be cleared. Select the websearch Tool and prompt the model for information it will not have e.g. Try the prompt:
What is the weather today in Brisbane ?In the playground this actually uses the Regular agent to call the Tool. The LLM makes its own decision to call the Tool. The tool returns a result to LLM and allows LLM to perform a new decision. This process loops until the LLM decides that a result can be provided to the user or certain conditions are met. The LLM produces a final result for the agent.
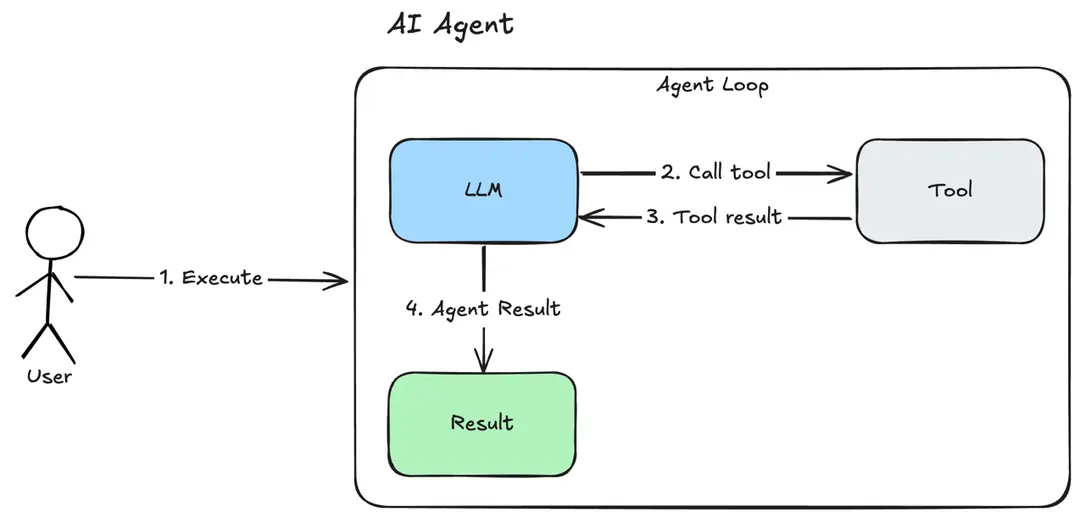
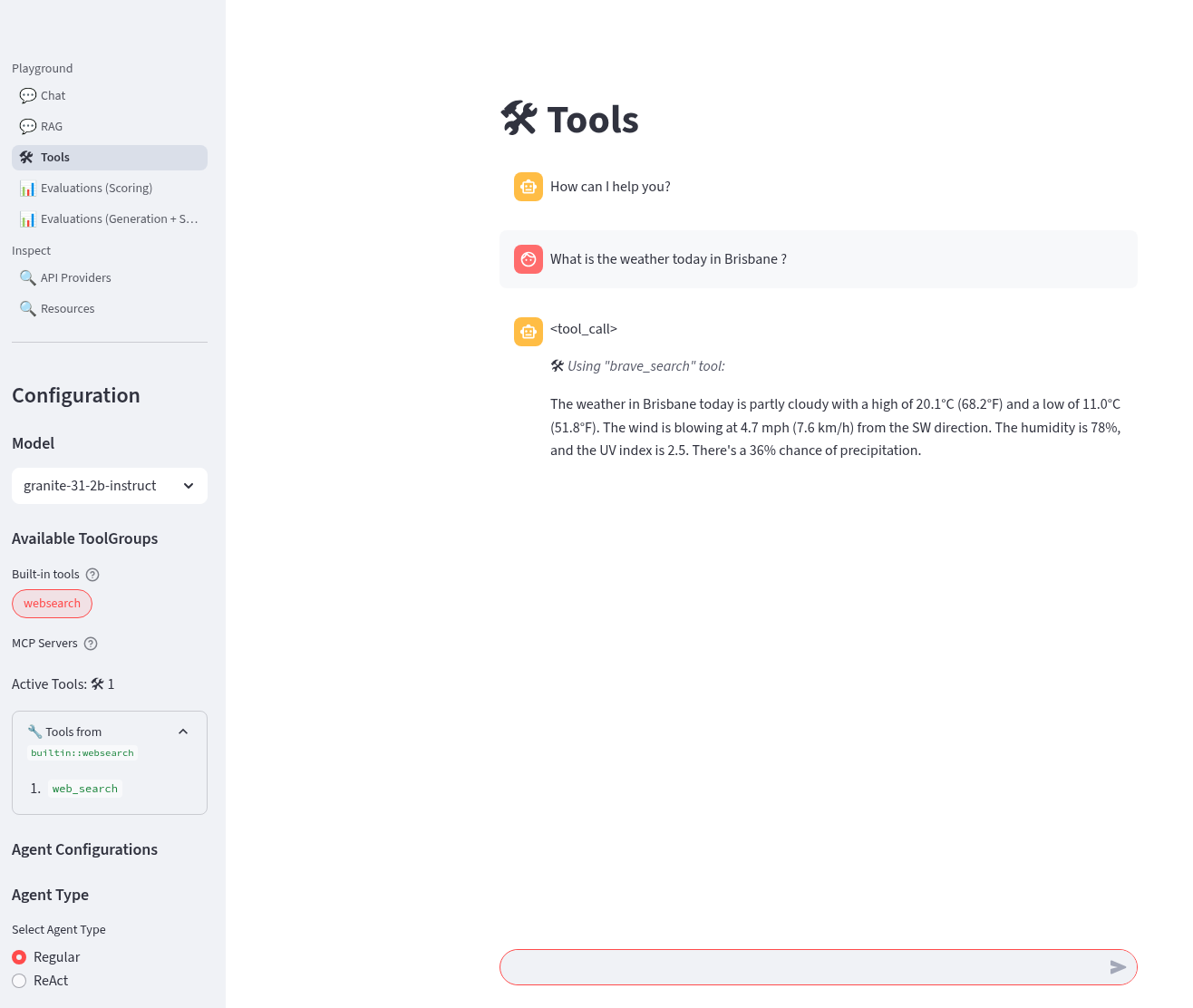
-
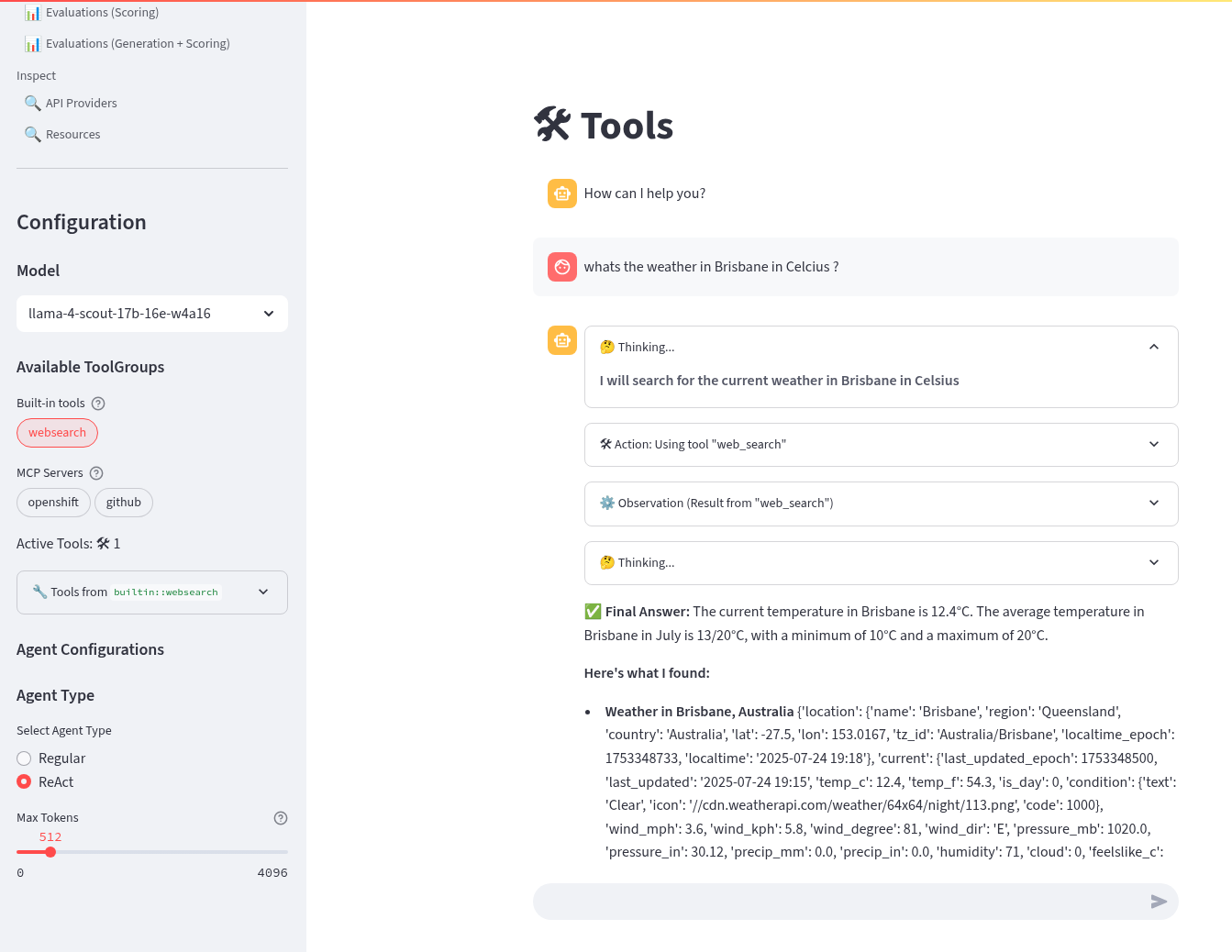
Try out the ReAct agent to call the tool with the same prompt:
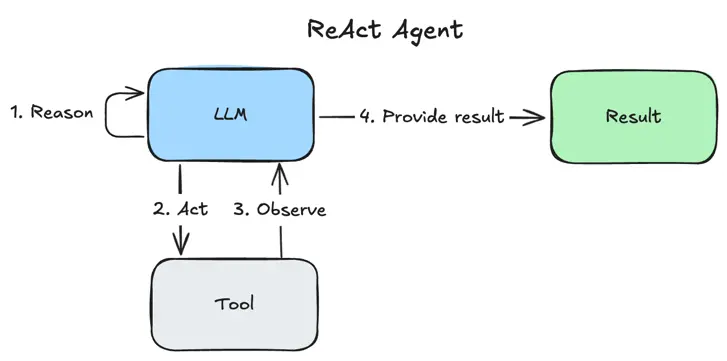
What is the weather today in Brisbane ?Notice that the agent first Reasons - where the LLM thinks about the data or tool results, Acts - where the LLM performs an action, LLM then Observes the result of the tool call, before returning the result. This is the essence of the ReAct agent pattern.
-
Done ✅
LlamaStack integrate with MaaS
By this point in time, we should be getting a feel for how to configure LlamaStack. Let’s add in our other models from the MaaS.
-
Open the MaaS configuration under the maas overlay. We can see the two MaaS models - llama-3-2-3b and llama-4-scout-17b-16e-w4a16 along with their "remote::vllm" provider entries.
kind: ConfigMap apiVersion: v1 metadata: name: llama-stack-config namespace: llama-stack data: run.yaml: | # Llama Stack configuration version: '2' image_name: vllm apis: - agents - inference - safety - tool_runtime - vector_io models: - metadata: {} model_id: granite-31-2b-instruct provider_id: vllm provider_model_id: granite-31-2b-instruct model_type: llm - metadata: {} model_id: llama-3-2-3b provider_id: vllm-llama-3-2-3b provider_model_id: llama-3-2-3b model_type: llm - metadata: {} model_id: llama-4-scout-17b-16e-w4a16 provider_id: vllm-llama-4-guard provider_model_id: llama-4-scout-17b-16e-w4a16 model_type: llm providers: agents: - provider_id: meta-reference provider_type: inline::meta-reference config: persistence_store: type: sqlite db_path: ${env.SQLITE_STORE_DIR:=~/.llama/distributions/starter}/agents_store.db responses_store: type: sqlite db_path: ${env.SQLITE_STORE_DIR:=~/.llama/distributions/starter}/responses_store.db inference: - provider_id: vllm provider_type: "remote::vllm" config: url: "https://granite-31-2b-instruct.vllm-server.svc.cluster.local/v1" name: llama3.2:1b context_length: 4096 tls_verify: false - provider_id: vllm-llama-3-2-3b provider_type: "remote::vllm" config: url: "https://llama-3-2-3b-maas-apicast-production.apps.prod.rhoai.rh-aiservices-bu.com:443/v1" max_tokens: 110000 api_token: ${env.LLAMA_3_2_3B_API_TOKEN} tls_verify: true - provider_id: vllm-llama-4-guard provider_type: "remote::vllm" config: url: "https://llama-4-scout-17b-16e-w4a16-maas-apicast-production.apps.prod.rhoai.rh-aiservices-bu.com:443/v1" max_tokens: 110000 api_token: ${env.LLAMA_4_SCOUT_17B_16E_W4A16_API_TOKEN} tls_verify: true tool_runtime: - provider_id: tavily-search provider_type: remote::tavily-search config: api_key: ${env.TAVILY_API_KEY} max_results: 3 tools: - name: builtin::websearch enabled: true tool_groups: - provider_id: tavily-search toolgroup_id: builtin::websearch server: port: 8321 -
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the maas/ folder
-
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with maas"; git push -
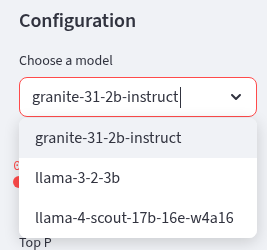
Refresh the playground in the browser. You should now be able to see three models, two from MaaS llama-3-2-3b, llama-4-scout-17b-16e-w4a16 and the default granite-31-2b-instruct model.
-
Try chatting to these new models. Do they both work ? The LLama4 model has a significant improvement in size and context length over the smaller models.
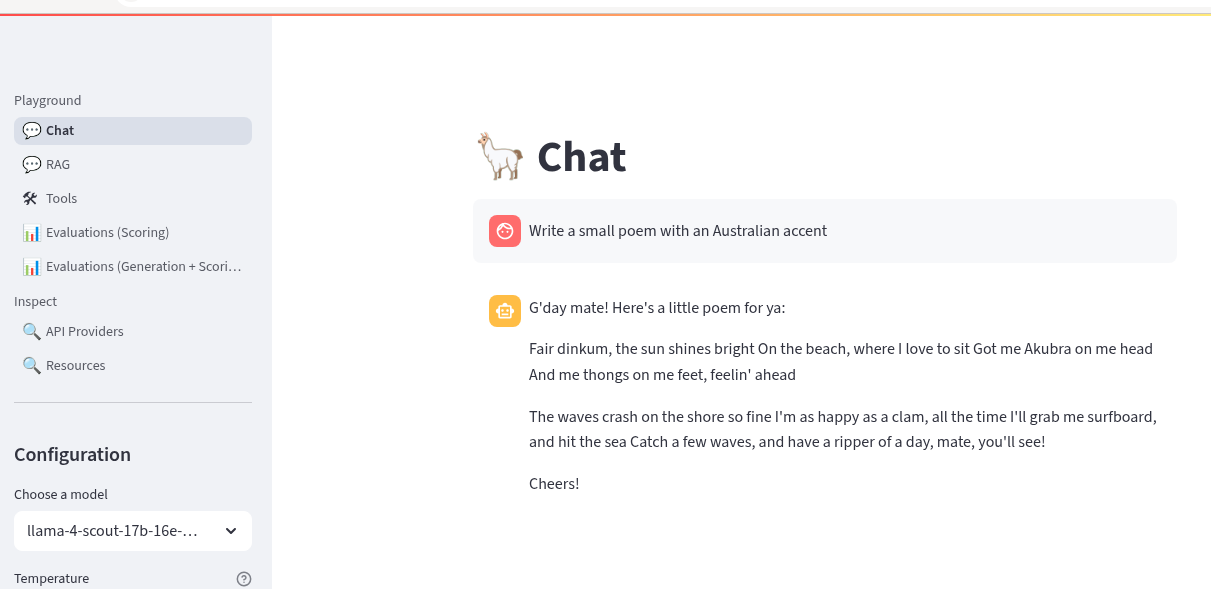
-
Done ✅
|
If one of the MaaS model fails, evaluate the stack trace error. It may be that the vLLM ServingRuntime or InferenceService server has not been correctly configured for tool calling. vLLM needs the correct arguments set to be able to correctly interpret tool calling prompts. If you check back on the model deployment code for the default model infra/applications/models/base/granite/granite-31-2b-vllm-oci.yaml you may notice these arguments to vLLM You would then have to talk with the MaaS team to set these correctly for your model. |
LlamaStack mcp::openshift
MCP is an upcoming, popular standard for tool discovery and execution. It is a protocol that allows tools to be dynamically discovered from an MCP endpoint and can be used to extend the agent’s capabilities.
First we need to deploy the pod that runs the mcp::openshift functions. Then we need to configure LlamaStack to use our first MCP tool that interacts with the OpenShift cluster. MCP servers are configured similarly to the tool and toolgroup provider.
-
Rename the file infra/app-of-apps/sno/mcp-openshift.yaml.undeploy → infra/app-of-apps/sno/mcp-openshift.yaml
-
Check this file into git
# Its not real unless its in git git add .; git commit -m "deploy mcp::openshift"; git push -
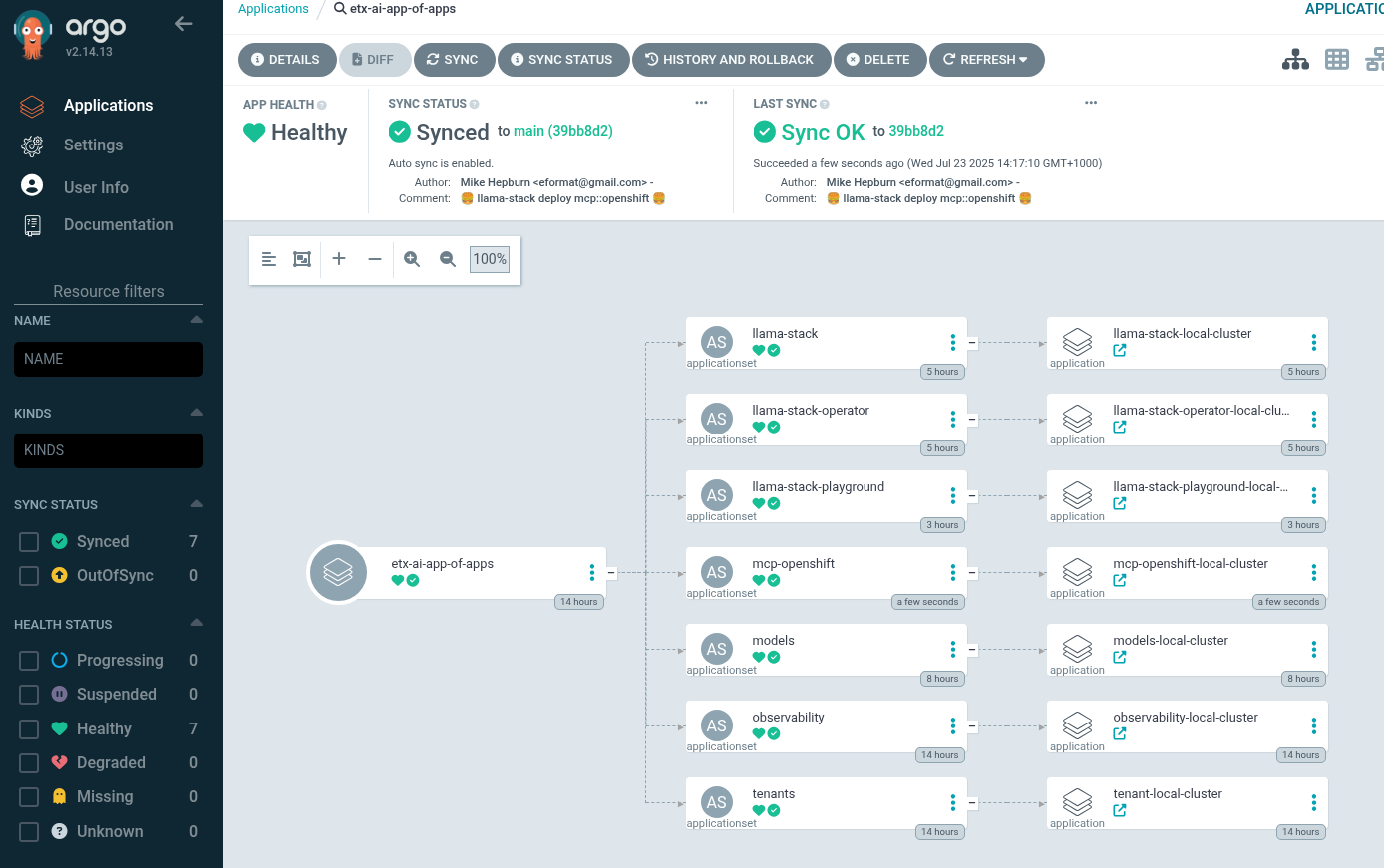
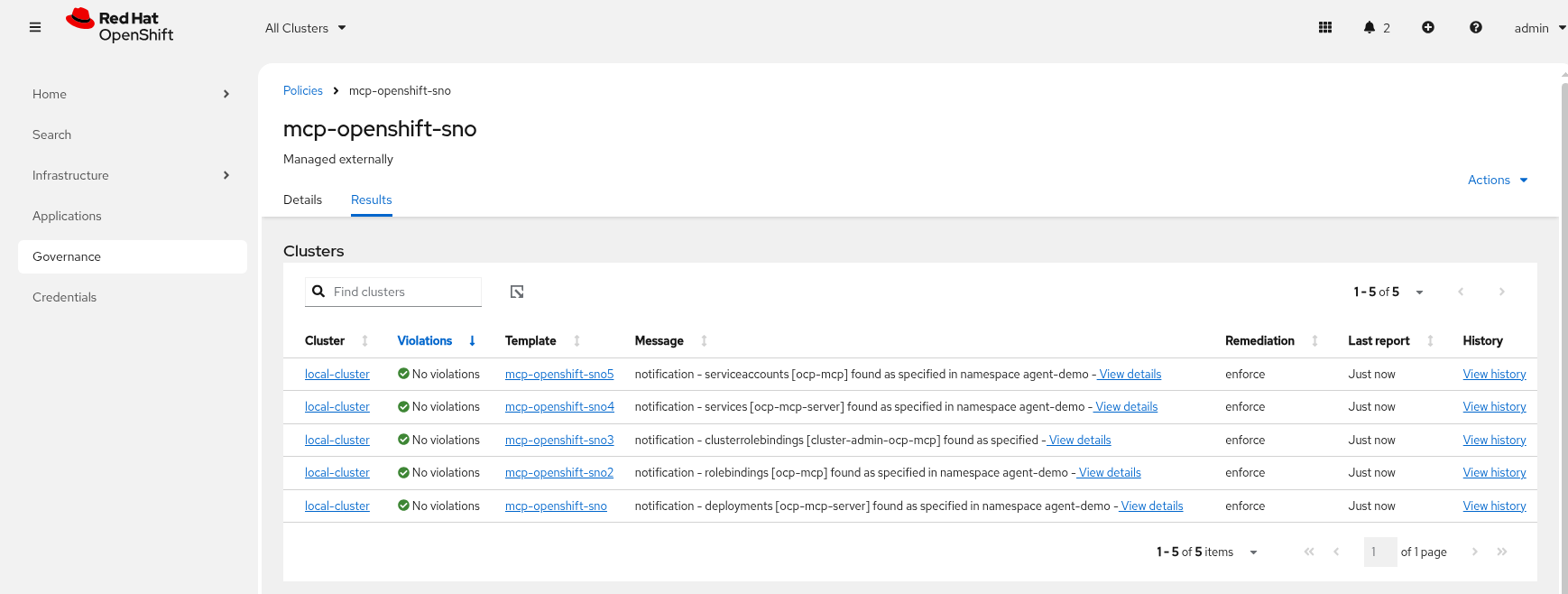
Check Argo CD and ACM and for the MCP Pod
-
Check MCP Pod is running OK, check its logs
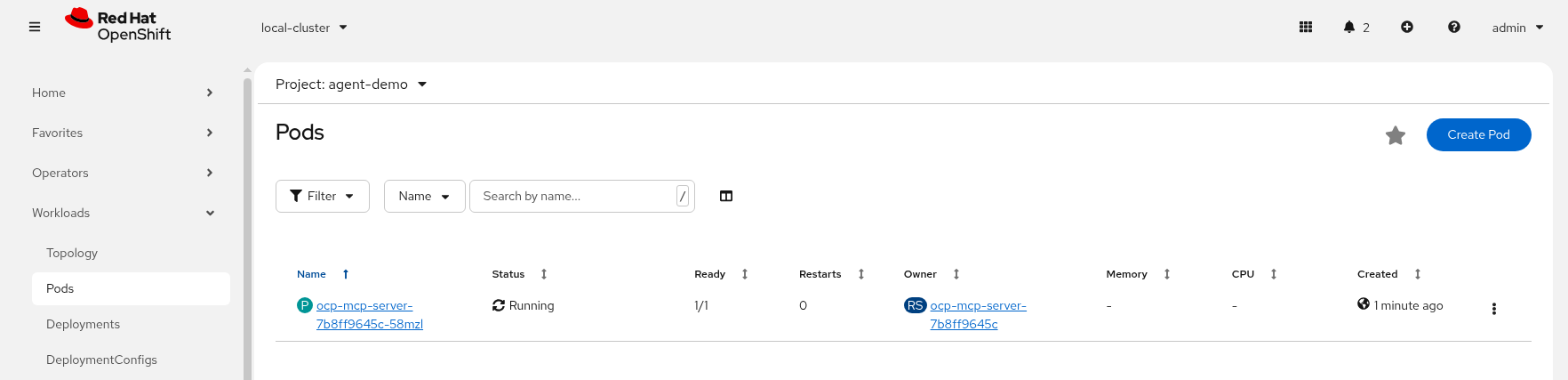
-
Next we need to configure LlamaStack. Open the mcp-openshift/configmap.yaml overlay and check where we add the tool runtime for MCP
tool_runtime: - provider_id: model-context-protocol provider_type: remote::model-context-protocol config: {} -
We also add in the tool group
tool_groups: - toolgroup_id: mcp::openshift provider_id: model-context-protocol -
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the mcp-openshift/ folder
-
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with mcp-openshift"; git push -
Refresh the playground in the browser. Select the Tools playground with the MCP Servers openshift, ReAct agent and Llama4 model. Try the prompt:
list pods using the label app=ocp-mcp-server in the agent-demo namespace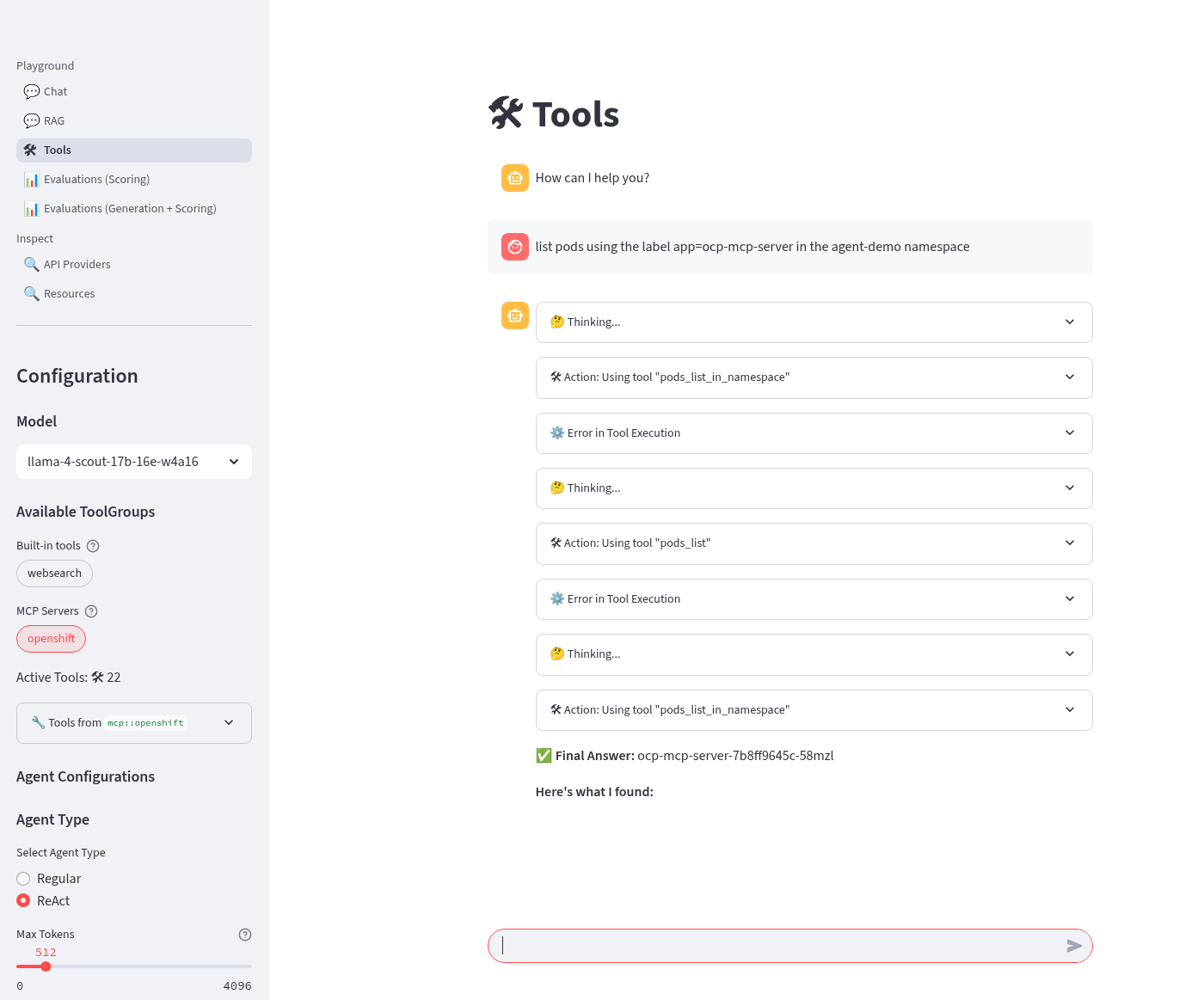
-
You will notice the the response has the Pod yaml included OK but fails to parse correctly in the llamastack-playground UI.
-
The pydantic errors can be seen in the playground pod logs.
oc -n llama-stack -c llama-stack-playground logs -l app.kubernetes.io/instance=llama-stack-playground -
Try this prompt instead using the same settings MCP Servers openshift, ReAct agent and Llama4 model
list pods using the label app=ocp-mcp-server in the agent-demo namespace. dont give me the pod yaml, rather just give me the pod name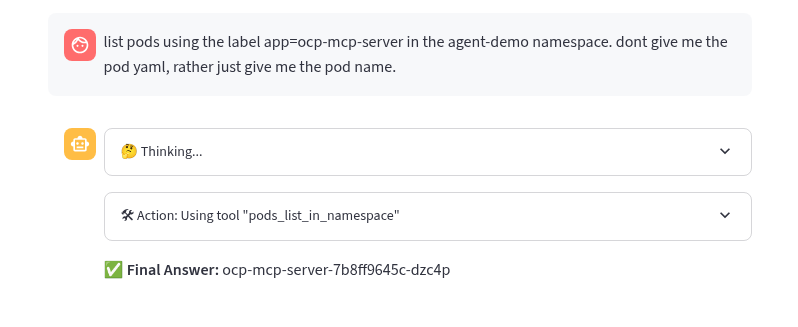
This works without any parsing errors in the playground OK
-
Try different models, agents and prompts. Not all of them work all of the time. This is a common problem with Tool calling and LLMs.
-
Done ✅
LlamaStack mcp::github
The last MCP Server we need to deploy interacts with GitHub. The configuration is very similar to MCP OpenShift.
-
Rename the file infra/app-of-apps/sno/mcp-github.yaml.undeploy → infra/app-of-apps/sno/mcp-github.yaml

-
Check this file into git
# Its not real unless its in git git add .; git commit -m "deploy mcp::github"; git push -
Check Argo CD and ACM and for the MCP Pod
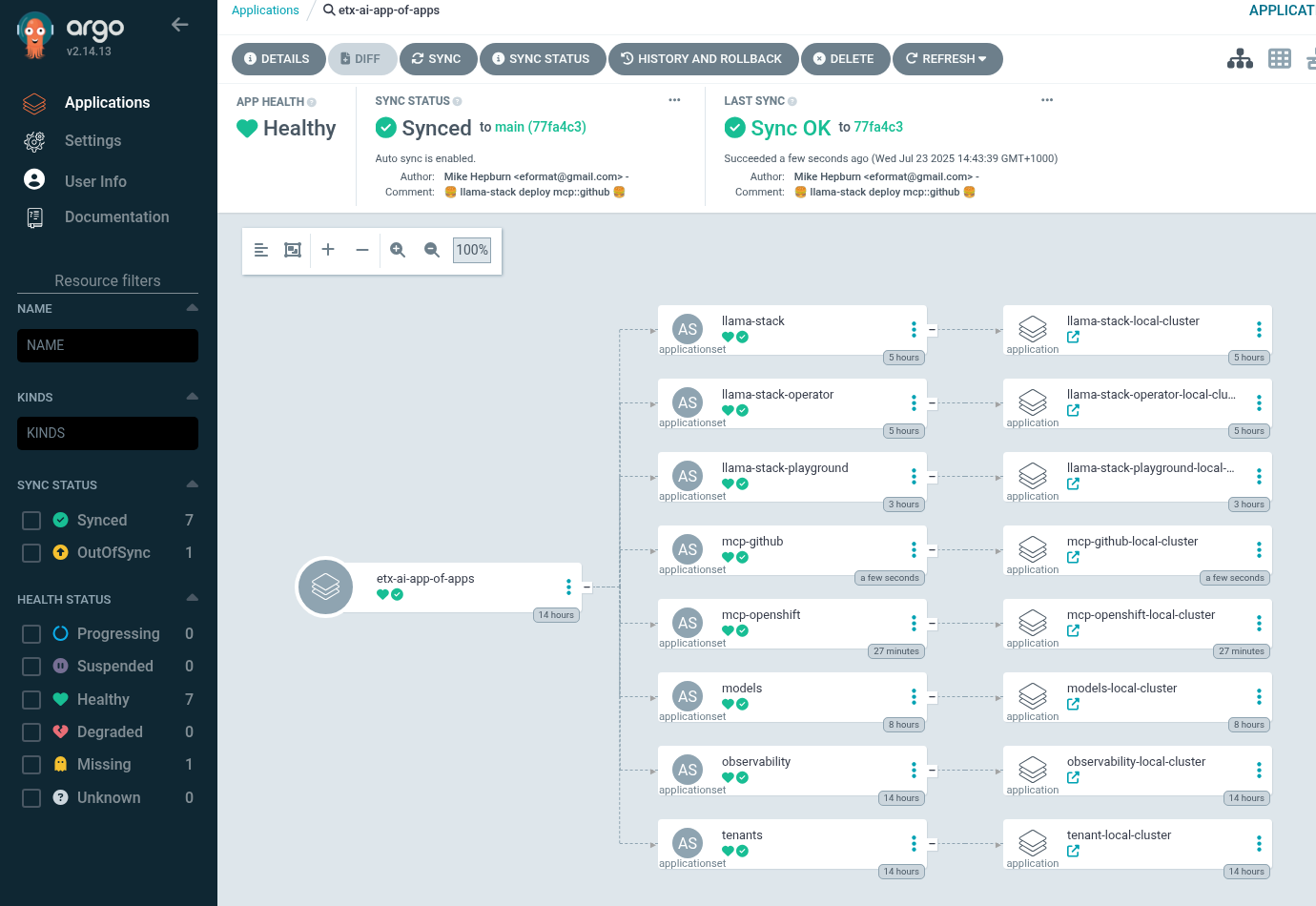
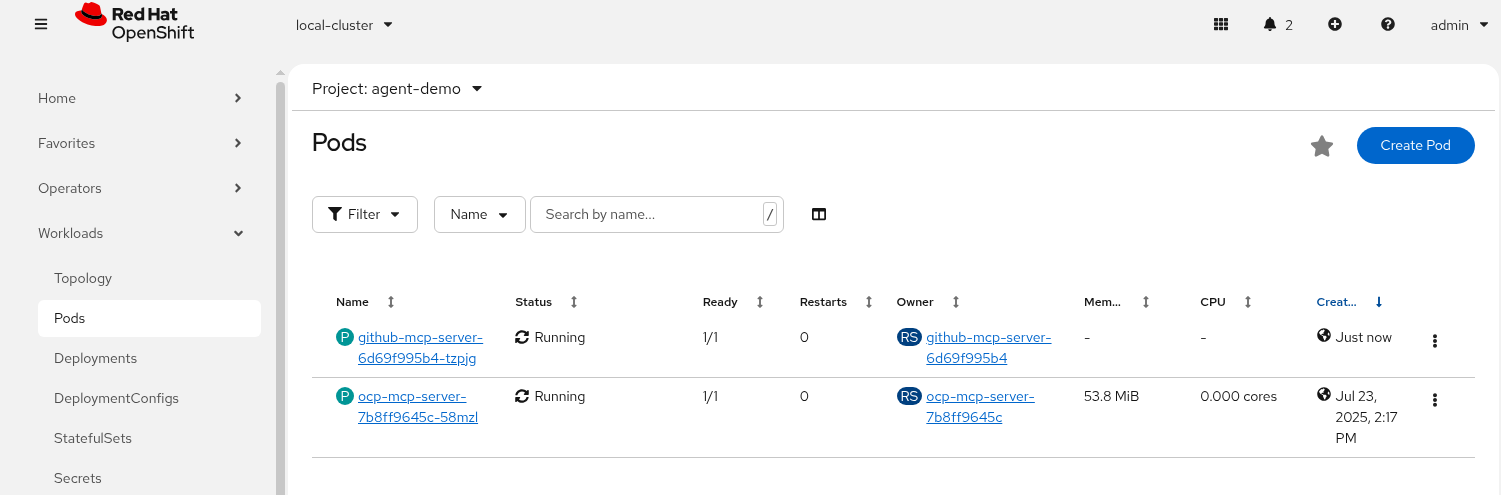
-
Check MCP Pod is running OK, check its logs
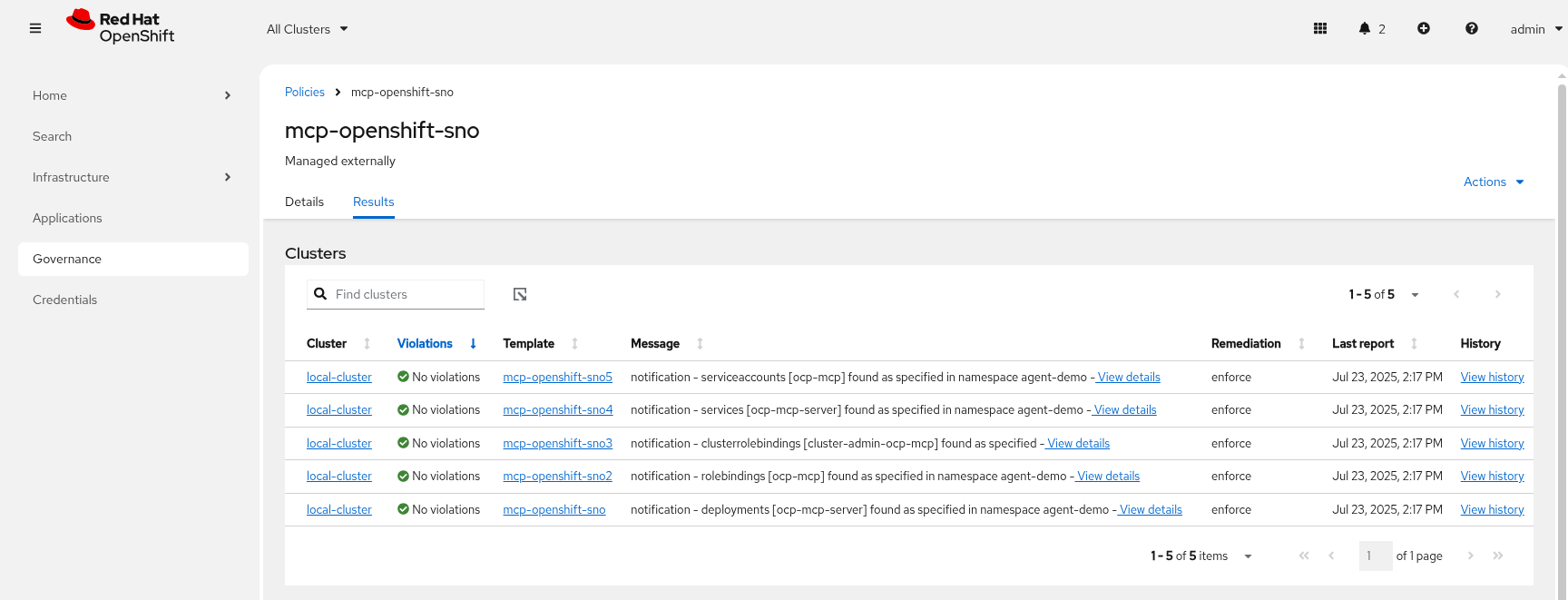
-
We add in the tool group. Notice that the URI for the MCP Server uses Server Sent Events (/sse).
tool_groups: - toolgroup_id: mcp::github provider_id: model-context-protocol mcp_endpoint: uri: http://github-mcp-server.agent-demo.svc.cluster.local:80/sse -
Edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the mcp-github/ folder

-
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with mcp-github"; git push -
Try this prompt instead using the same settings MCP Servers openshift, ReAct agent and Llama4 model
-
Refresh the playground in the browser. Select the Tools playground with the MCP Servers github, ReAct agent and Llama4 model. Try the prompt (replace the github user with your user).
List the branches from ${YOUR_GITHUB_USER}/etx-agentic-ai repo.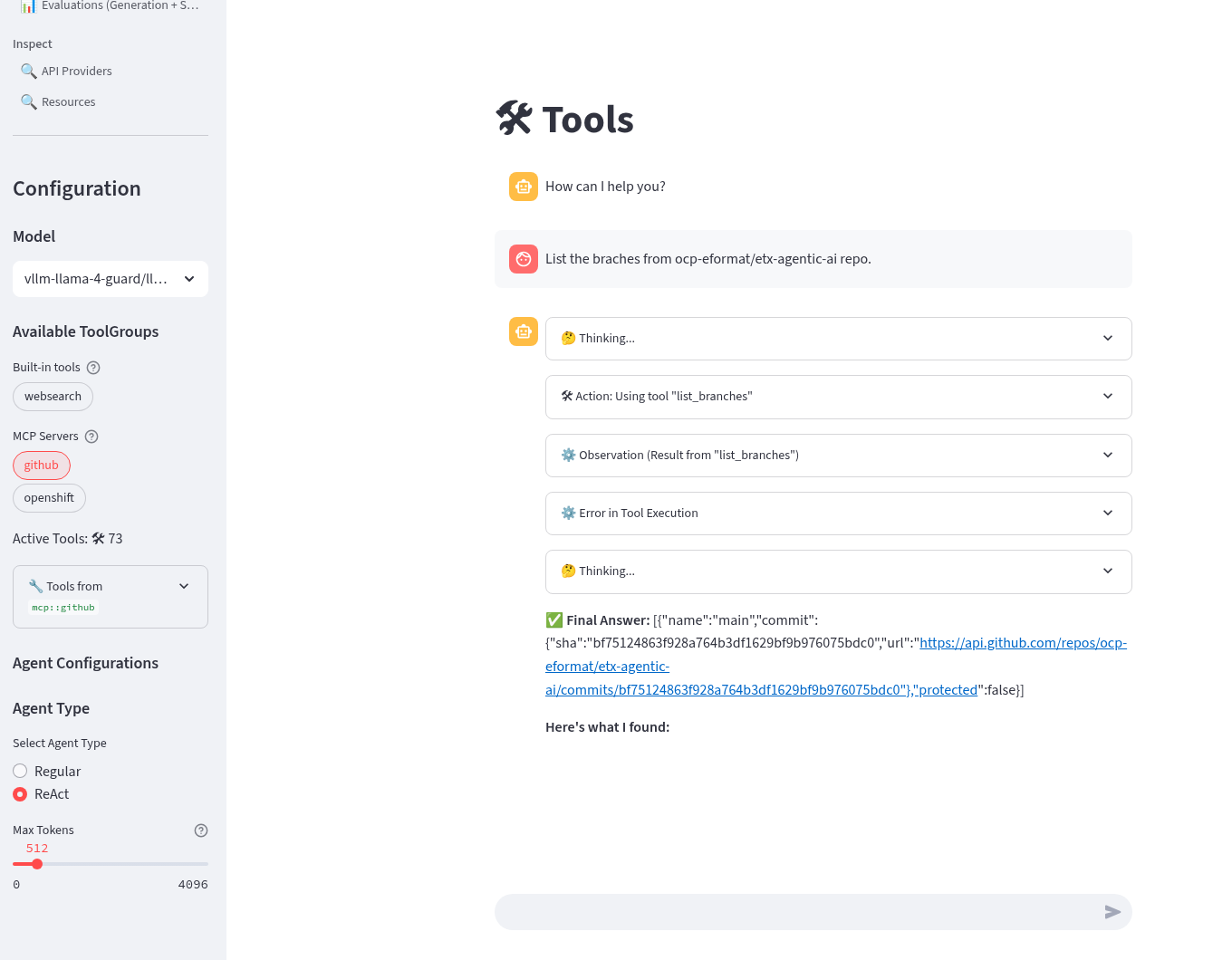
You can see also the response in the pod logs for the mcp::github server in the agent-demo namespace if you wish to debug any further.
-
Try different models, agents and prompts. Not all of them work all of the time. This is a common problem with Tool calling and LLMs
-
Done ✅
LlamaStack Observability
LlamaStack integrates with the Observability stack we deployed as part of the bootstrap. The observability stack has a lot of moving parts. Traces are sent from LlamaStack via OTEL to a Tempo sink endpoint. We can then view traces in OpenShift using the Observe > Traces dashboard.
-
To configure telemetry on our LlamaStack server, edit the file infra/applications/llama-stack/overlay/policy-generator-config.yaml to point to the sno/ folder. This is the final configuration for our use case.

-
Checking the base ConfigMap shows the telemetry stanza with the service name, sinks and the OTEL Tracing endpoint which is set as an environment variable on the Deployment
telemetry: - provider_id: meta-reference provider_type: inline::meta-reference config: service_name: ${env.OTEL_SERVICE_NAME:=llama-stack} sinks: ${env.TELEMETRY_SINKS:=console, sqlite, otel_metric, otel_trace} otel_exporter_otlp_endpoint: ${env.OTEL_EXPORTER_OTLP_ENDPOINT:=} sqlite_db_path: ${env.SQLITE_DB_PATH:=~/.llama/distributions/remote-vllm/trace_store.db} -
Check these files into git
# Its not real unless its in git git add .; git commit -m "deploy llama-stack with telemetry"; git push -
Refresh the playground in the browser. Select the Tools playground and select websearch, the MCP github Server and MCP OpenShift tool, ReAct agent and Llama4 model. Try out some of the previous prompting that include Tool calls to generate some traces.
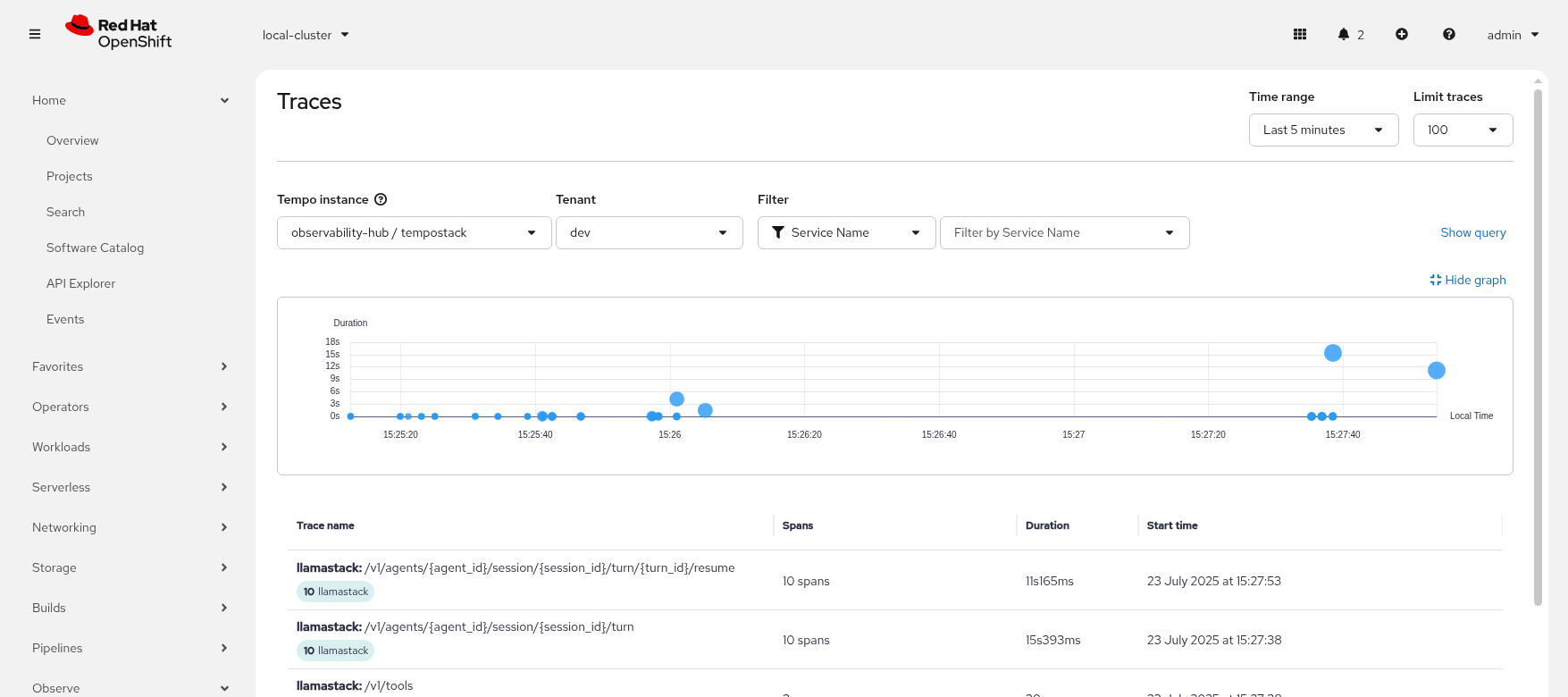
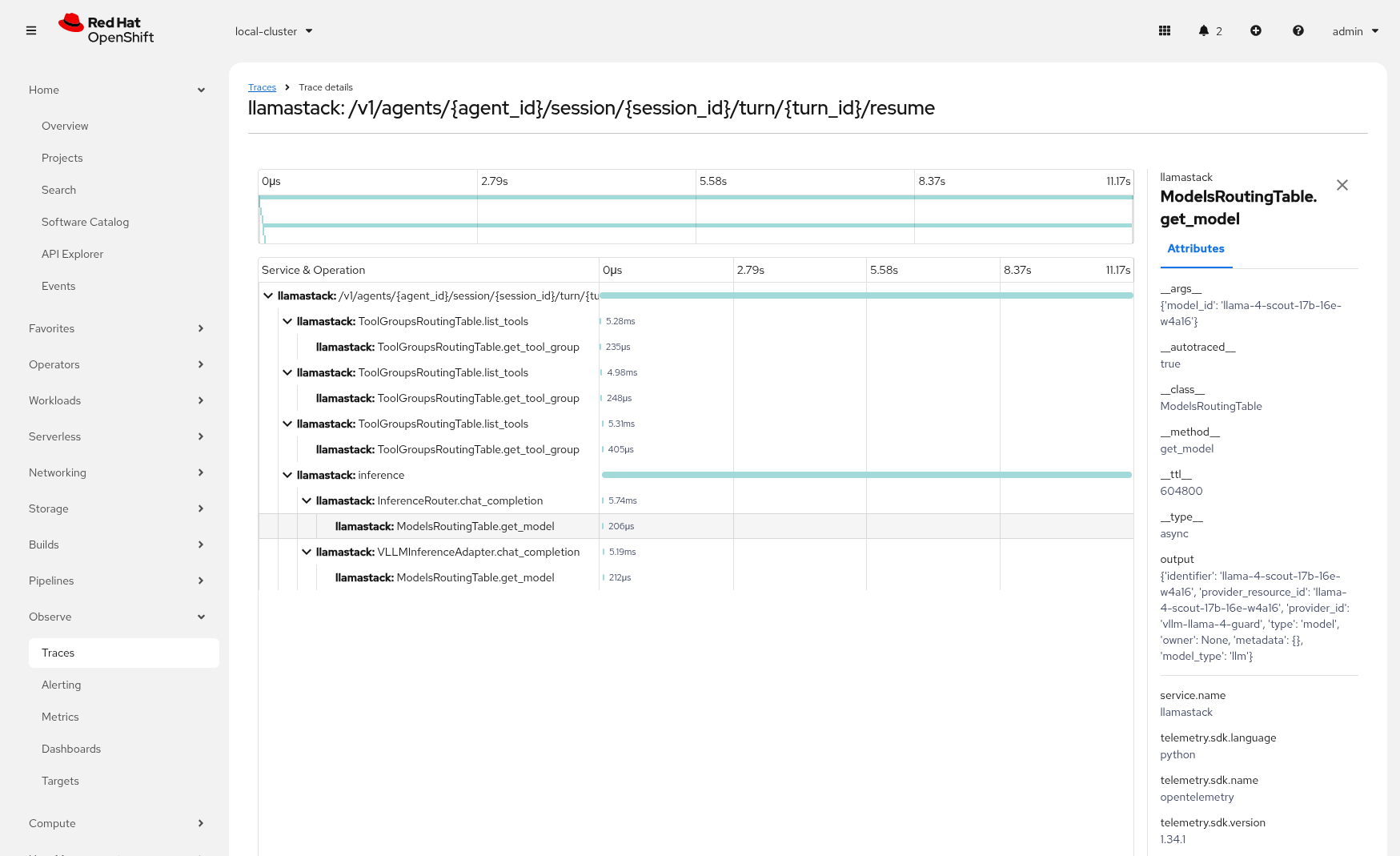
-
Done ✅
LlamaStack Configured
-
Check the completed LlamaStack configuration
llama-stack-client providers listINFO:httpx:HTTP Request: GET http://localhost:8321/v1/providers "HTTP/1.1 200 OK" ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ API ┃ Provider ID ┃ Provider Type ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ scoring │ basic │ inline::basic │ │ scoring │ llm-as-judge │ inline::llm-as-judge │ │ agents │ meta-reference │ inline::meta-reference │ │ inference │ vllm │ remote::vllm │ │ inference │ vllm-llama-3-2-3b │ remote::vllm │ │ inference │ vllm-llama-4-guard │ remote::vllm │ │ inference │ sentence-transformers │ inline::sentence-transformers │ │ tool_runtime │ model-context-protocol │ remote::model-context-protocol │ │ tool_runtime │ brave-search │ remote::brave-search │ │ tool_runtime │ tavily-search │ remote::tavily-search │ │ telemetry │ meta-reference │ inline::meta-reference │ └──────────────┴────────────────────────┴────────────────────────────────┘llama-stack-client models listINFO:httpx:HTTP Request: GET http://localhost:8321/v1/models "HTTP/1.1 200 OK" Available Models ┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ model_type ┃ identifier ┃ provider_resource_id ┃ metadata ┃ provider_id ┃ ┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ llm │ vllm/granite-31-2b-instruct │ granite-31-2b-instruct │ │ vllm │ ├─────────────────┼────────────────────────────────────────────────────────────────────┼─────────────────────────────────────────┼─────────────────────────────────────────────┼──────────────────────────────┤ │ llm │ vllm-llama-3-2-3b/llama-3-2-3b │ llama-3-2-3b │ │ vllm-llama-3-2-3b │ ├─────────────────┼────────────────────────────────────────────────────────────────────┼─────────────────────────────────────────┼─────────────────────────────────────────────┼──────────────────────────────┤ │ llm │ vllm-llama-4-guard/llama-4-scout-17b-16e-w4a16 │ llama-4-scout-17b-16e-w4a16 │ │ vllm-llama-4-guard │ ├─────────────────┼────────────────────────────────────────────────────────────────────┼─────────────────────────────────────────┼─────────────────────────────────────────────┼──────────────────────────────┤ │ embedding │ sentence-transformers/all-MiniLM-L6-v2 │ all-MiniLM-L6-v2 │ {'embedding_dimension': 384.0} │ sentence-transformers │ └─────────────────┴────────────────────────────────────────────────────────────────────┴─────────────────────────────────────────┴─────────────────────────────────────────────┴──────────────────────────────┘ Total models: 4 -
Done ✅
Using the DataScienceCluster Resource to configure the LlamaStack Operator
This section is for information only and should be supported in 2.23+ of RHOAI.
|
VERSION 2.22 DOES NOT HAVE USERCONFIG MAP OVERRIDE SO DO NOT USE DSC YET - SCHEDULED FOR 2.23 With the latest version of RHOAI 2.22.0+ we can use the built in DSC (Data Science Cluster) mechanism to deploy the operator.
|
(Optional) Bonus Extension Exercise
⛷️ For the adventurous who like to go off-piste. Try to configure the RAG tool in LlamaStack and LlamaStack Playground using milvus as the vector store provider. ⛷️
|
We have left some code that is commented out and undeployed to help you get to the bottom of the ski run. Good Luck 🫡
|
Using LlamaStack Playground for Use Case prompting
Use the Playground for our actual Use Case prompting (requires pipeline failure pods). We can try out various prompts to see what works best. Here are some examples - you will need to change the pod name.
Search for pod logs
-
Model: llama-4-scout-17b-16e-w4a16
-
Agent Type: ReAct
-
Tools: mcp::openshift
Query the namespace pod for a pod error; copy-paste search for solution to error logs
Try this prompt (replace the pod name for the java-app-build-run-bad- in your demo-pipeline namespace)
Review the OpenShift logs for the pod 'java-app-build-run-bad-7rdzn-build-pod', in the 'demo-pipeline' namespace.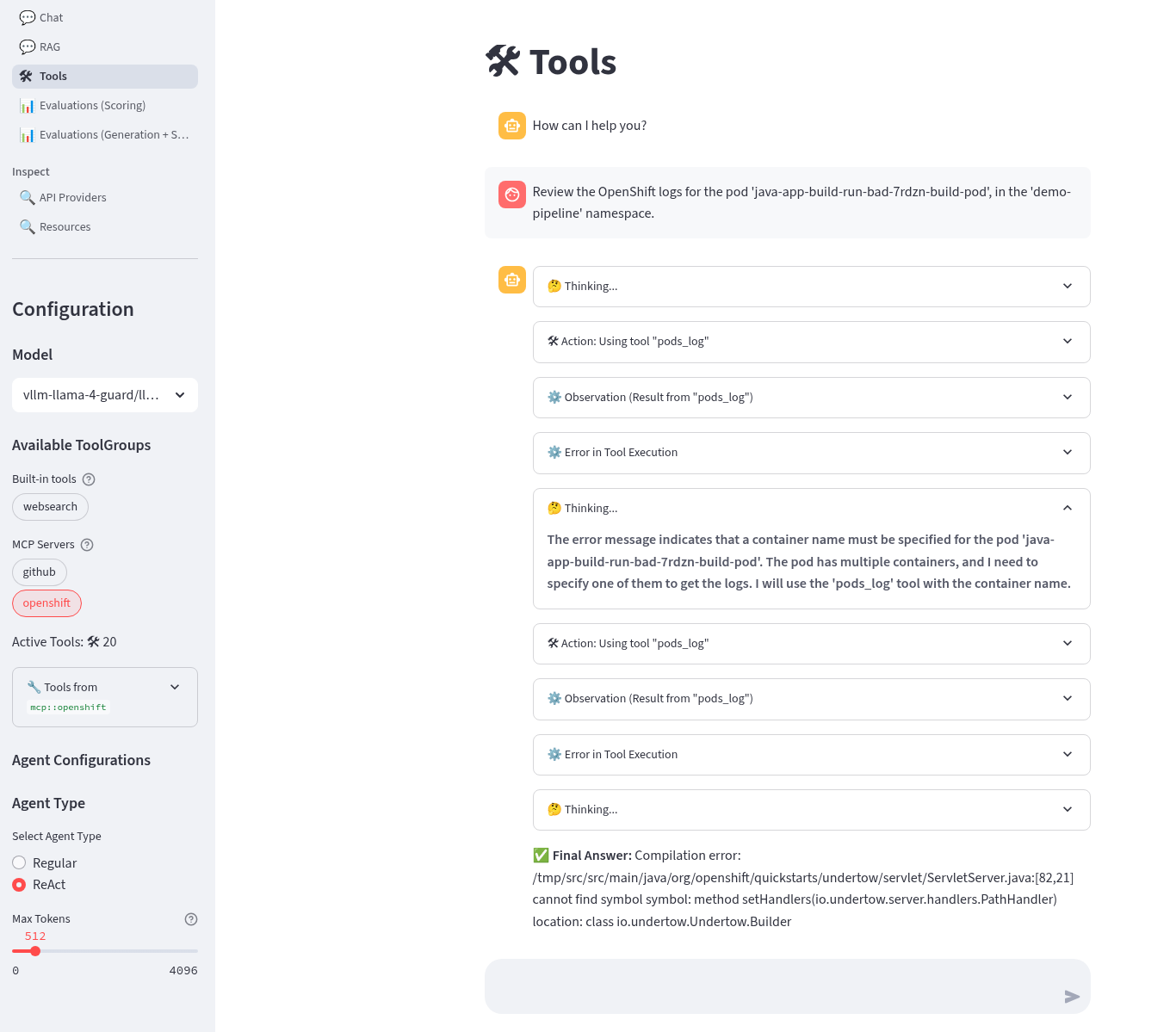
The agent reasoned correctly about the need to format the tool call with a container name as well
Try this prompt (replace the pod name for the java-app-build-run-bad- in your demo-pipeline namespace)
Review the OpenShift logs for the container 'step-s2i-build' in pod 'java-app-build-run-bad-7rdzn-build-pod', in the 'demo-pipeline' namespace.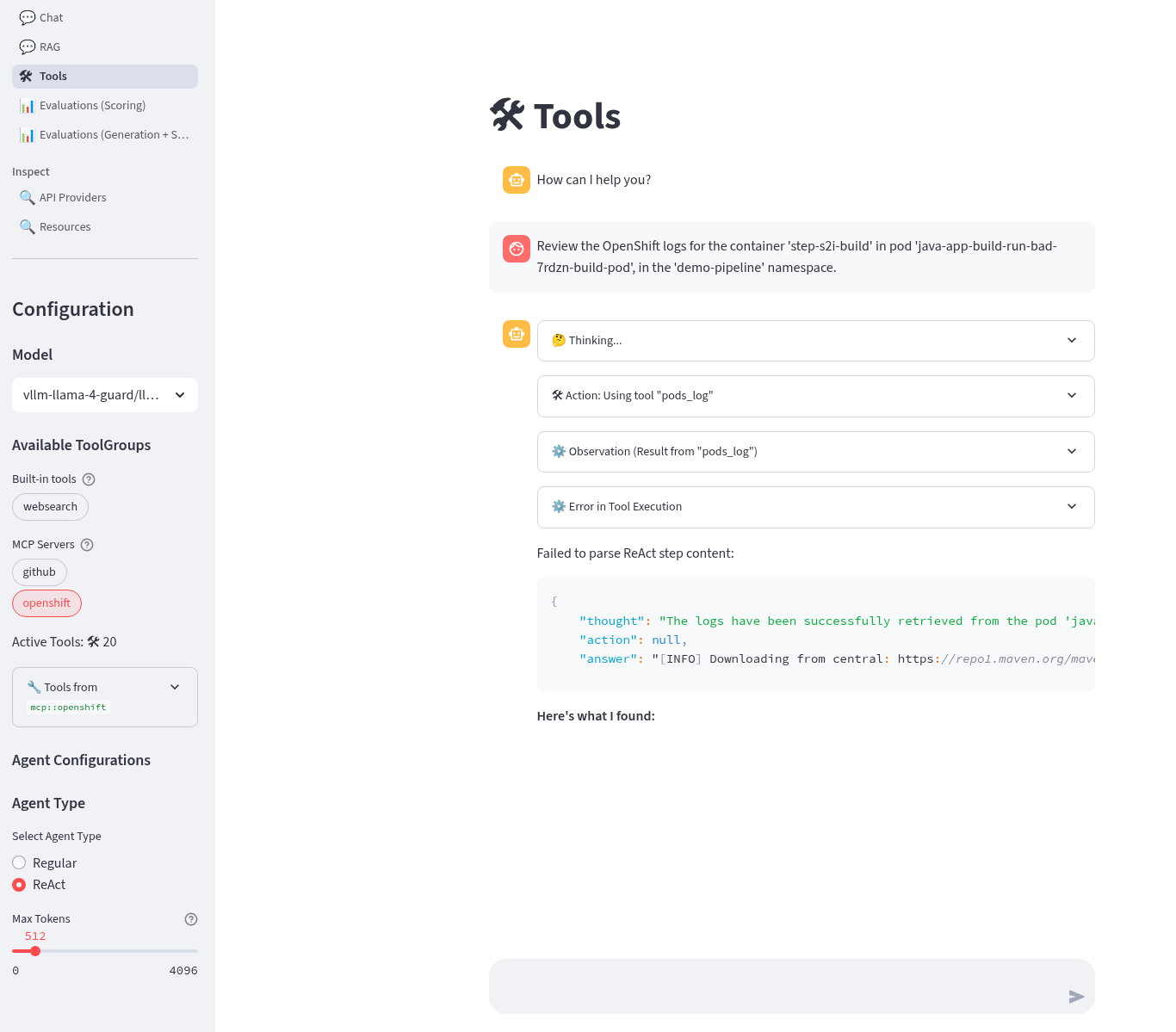
Supplying the container name means less agent turns, less error prone
Search for pod logs and websearch error summary
-
Model: llama-4-scout-17b-16e-w4a16
-
Agent Type: ReAct
-
Tools: mcp::openshift, websearch
Try this prompt (replace the pod name for the java-app-build-run-bad- in your demo-pipeline namespace)
Review the OpenShift logs for the container 'step-s2i-build' in pod 'java-app-build-run-bad-7rdzn-build-pod', in the 'demo-pipeline' namespace. If the logs indicate an error search for the top OpenShift solution. Create a summary message with the category and explanation of the error.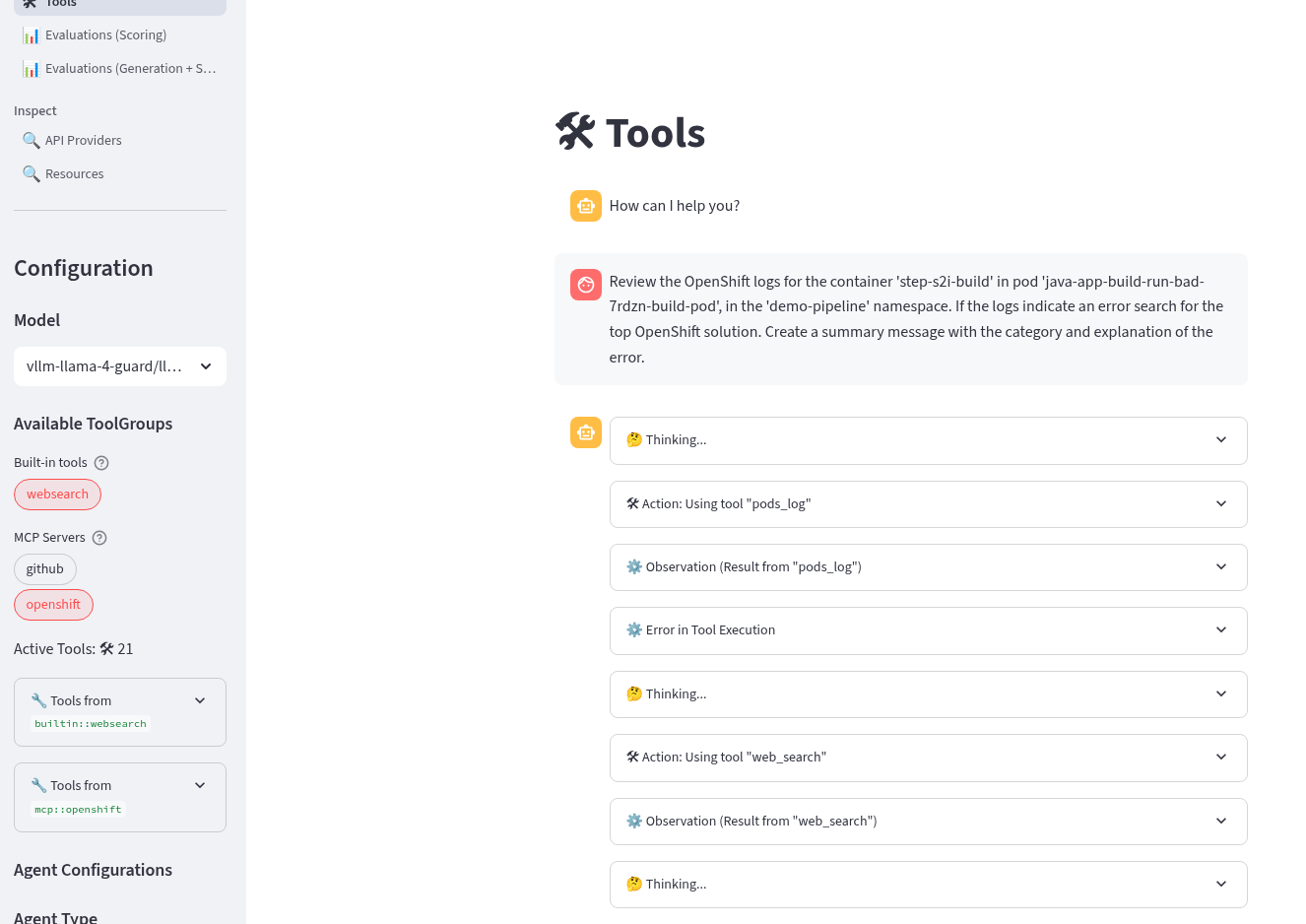
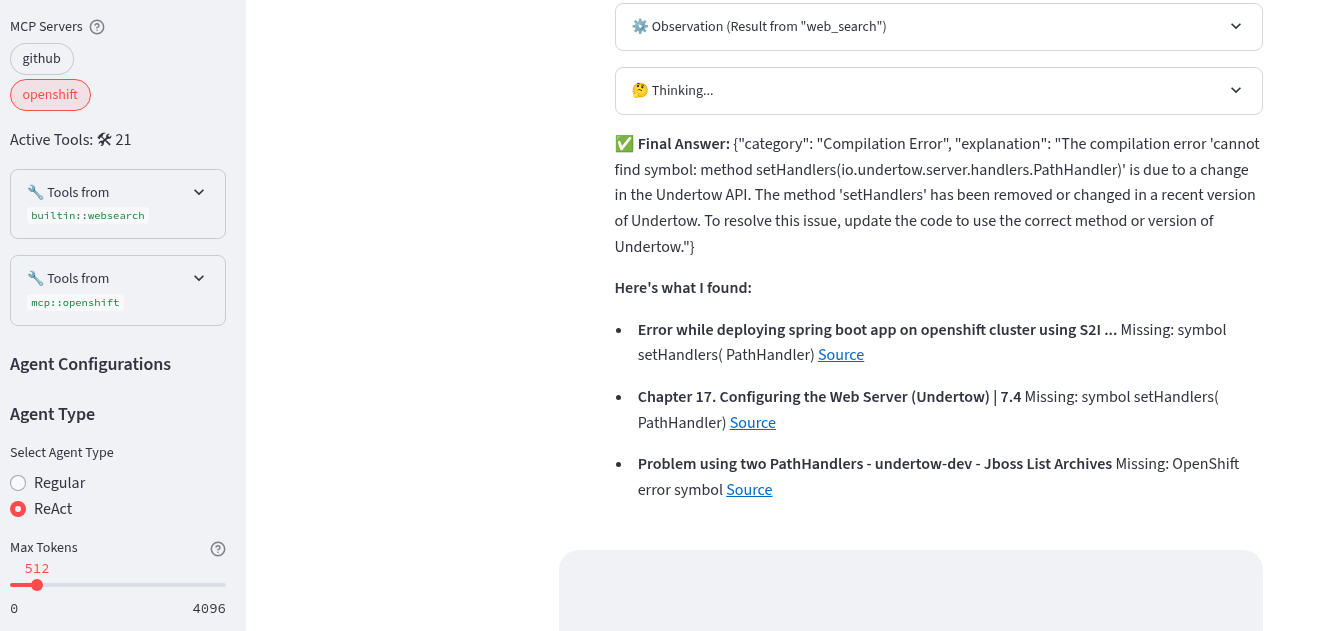
The Agent retrieved the pod logs and performed a websearch
Compare the results to the actual pod logs.
oc -n demo-pipeline -c step-s2i-build logs java-app-build-run-bad-7rdzn-build-pod
Create a GitHub issue
-
Model: llama-4-scout-17b-16e-w4a16
-
Agent Type: ReAct
-
Tools: mcp::github
Create a GitHub issue, add add issue comments
Try this prompt (replace the github user with your user).
Create a github issue for a fake error in the ${YOUR_GITHUB_USER}/etx-agentic-ai repo and assign it to ${YOUR_GITHUB_USER}.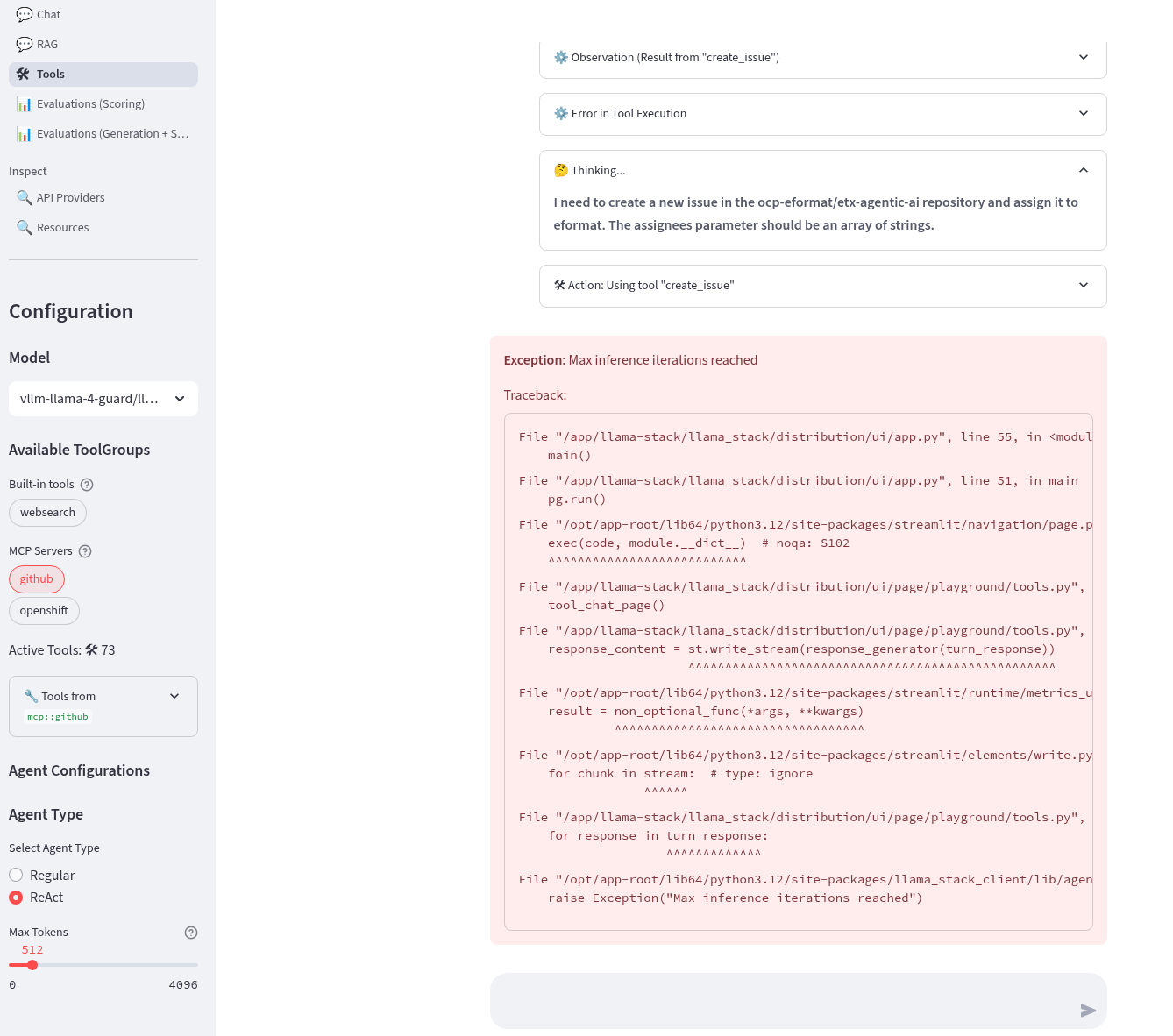
This fails due to parsing json arrays as strings. Try this prompt (replace YOUR_GITHUB_USER with your user).
Create a github issue using these parameters {"name":"create_issue","arguments":{"owner":"${YOUR_GITHUB_USER}","repo":"etx-agentic-ai","title":"Fake Error: Agentic AI Service Unresponsive","body":"The Agentic AI service is not responding. This is a fake error report."}}} DO NOT add any optional parameters.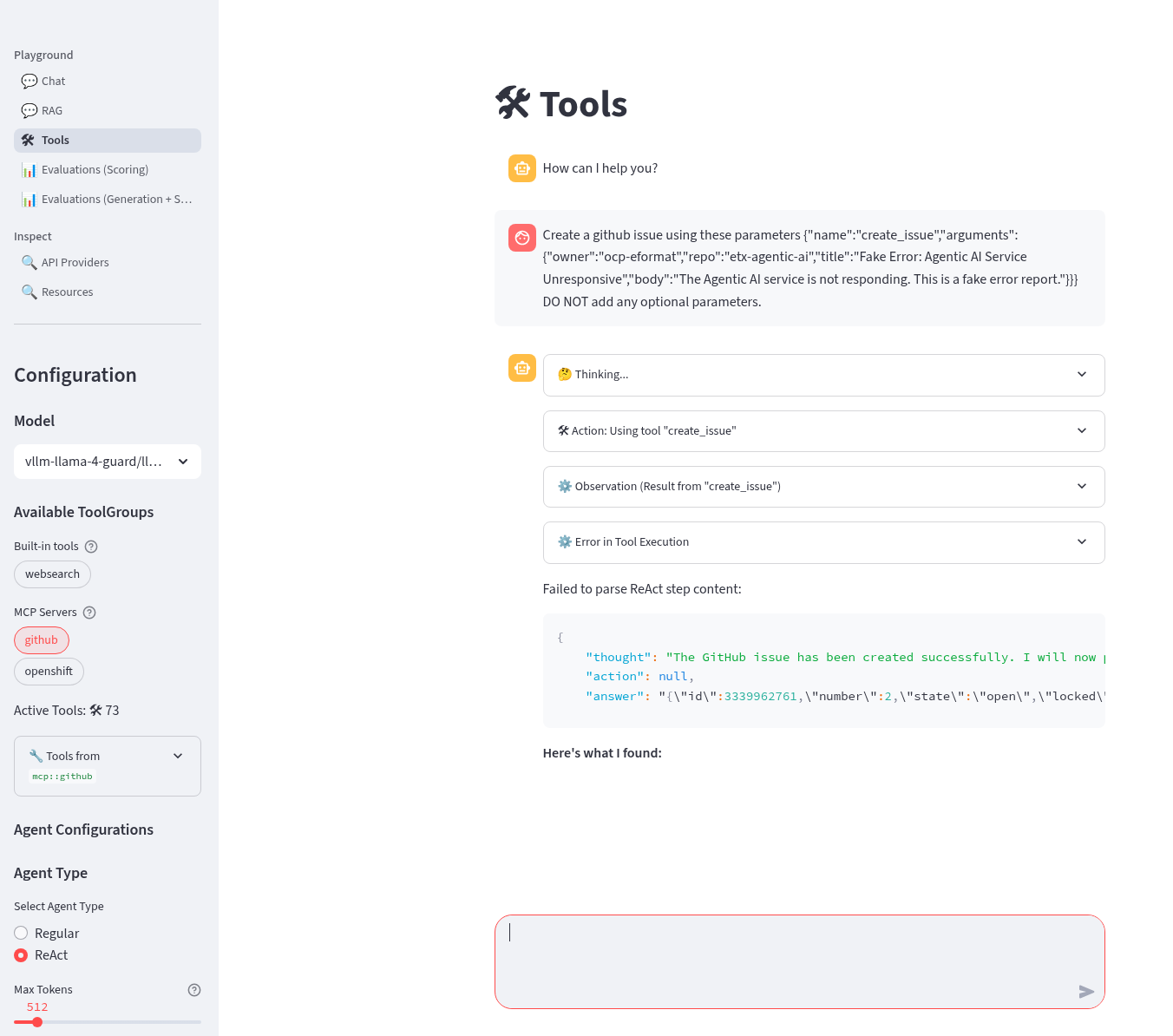
This is successful but may take a few turns to get the tool call right
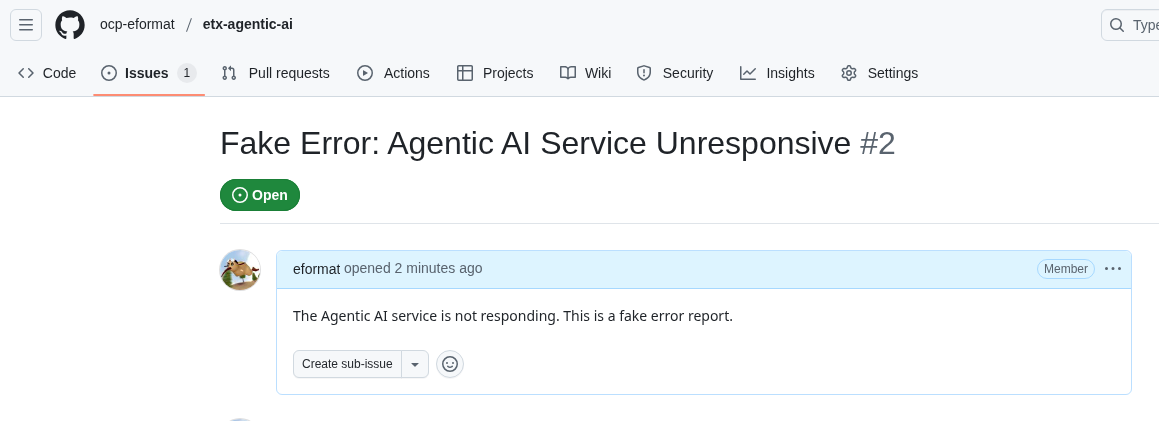
Create the Final Prompt
-
Model: llama-4-scout-17b-16e-w4a16
-
Agent Type: ReAct
-
Tools: mcp::openshift, mcp::github
Prompt engineering; let’s try and create a prompt that chains together the different tasks together, analyze the pod logs then generate a github issue 🍺 Try this prompt (replace YOUR_GITHUB_USER with your user, replace the pod name for the java-app-build-run-bad- in your demo-pipeline namespace)
You are an expert OpenShift administrator. Your task is to analyze pod logs, summarize the error, and generate a JSON object to create a GitHub issue for tracking. Follow the format in the examples below. --- EXAMPLE 1: Input: The logs for pod 'frontend-v2-abcde' in namespace 'webapp' show: ImagePullBackOff: Back-off pulling image 'my-registry/frontend:latest'. Output: The pod is in an **ImagePullBackOff** state. This means Kubernetes could not pull the container image 'my-registry/frontend:latest', likely due to an incorrect image tag or authentication issues. {"name":"create_issue","arguments":{"owner":"${YOUR_GITHUB_USER}","repo":"etx-agentic-ai","title":"Issue with Etx pipeline","body":"### Cluster/namespace location\\nwebapp/frontend-v2-abcde\\n\\n### Summary of the problem\\nThe pod is failing to start due to an ImagePullBackOff error.\\n\\n### Detailed error/code\\nImagePullBackOff: Back-off pulling image 'my-registry/frontend:latest'\\n\\n### Possible solutions\\n1. Verify the image tag 'latest' exists in the 'my-registry/frontend' repository.\\n2. Check for authentication errors with the image registry."}} --- EXAMPLE 2: Input: The logs for pod 'data-processor-xyz' in namespace 'pipelines' show: CrashLoopBackOff. Last state: OOMKilled. Output: The pod is in a **CrashLoopBackOff** state because it was **OOMKilled**. The container tried to use more memory than its configured limit. {"name":"create_issue","arguments":{"owner":"${YOUR_GITHUB_USER}","repo":"etx-agentic-ai","title":"Issue with Etx pipeline","body":"### Cluster/namespace location\\npipelines/data-processor-xyz\\n\\n### Summary of the problem\\nThe pod is in a CrashLoopBackOff state because it was OOMKilled (Out of Memory).\\n\\n### Detailed error/code\\nCrashLoopBackOff, Last state: OOMKilled\\n\\n### Possible solutions\\n1. Increase the memory limit in the pod's deployment configuration.\\n2. Analyze the application for memory leaks."}} --- NOW, YOUR TURN: Input: Review the OpenShift logs for the container 'step-s2i-build' for the pod 'java-app-build-run-bad-7rdzn-build-pod' in the 'demo-pipeline' namespace. If the logs indicate an error, search for the solution, create a summary message with the category and explanation of the error, and create a Github issue using {"name":"create_issue","arguments":{"owner":"${YOUR_GITHUB_USER}","repo":"etx-agentic-ai","title":"Issue with Etx pipeline","body":"<summary of the error>"}}. DO NOT add any optional parameters. ONLY tail the last 10 lines of the pod, no more. The JSON object formatted EXACTLY as outlined above.The final prompt linking pod log errors and github
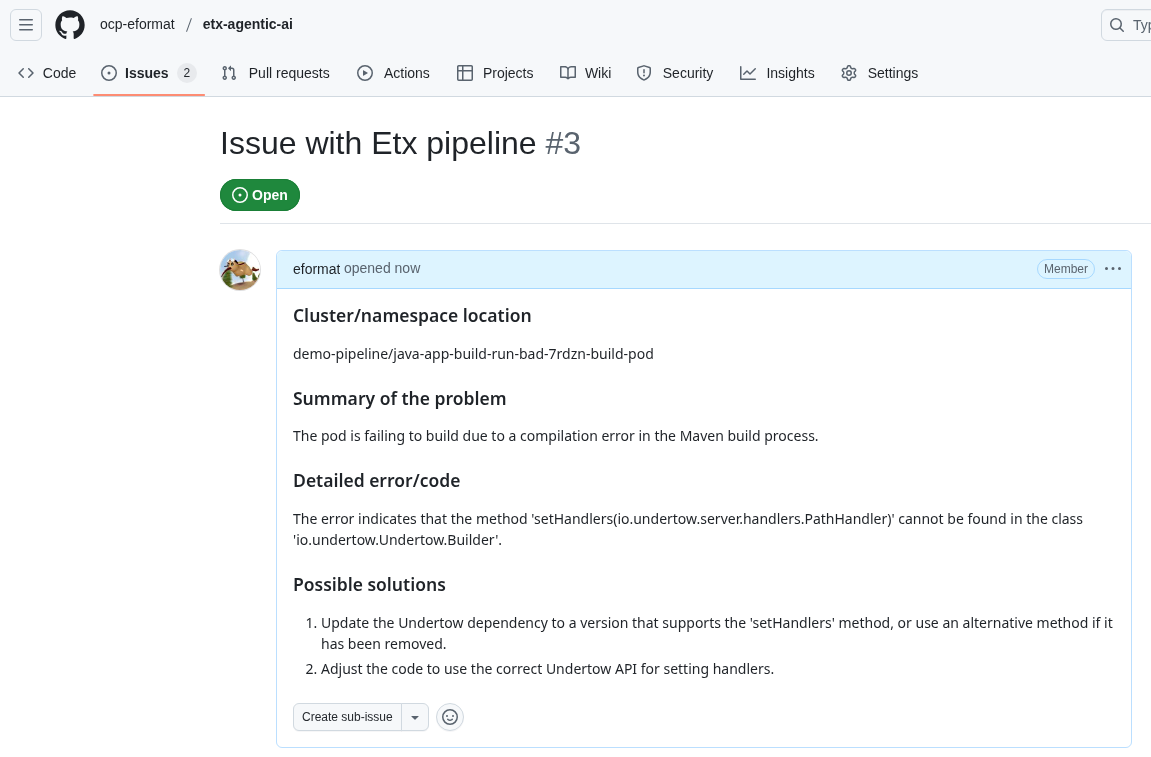
And the GitHub issue successfully created 🏆
-
Done ✅
-
Artifacts to carry forward
-
Selected model and endpoint details (Playground URL, model id)
-
Finalized system prompt and example user prompts used in Playground
-
Tooling decisions (builtin websearch enabled, MCP servers registered)
-
Any safety/guardrail parameters you validated
-
Notes/screenshots of successful Playground runs